

The Bottom Line
GPT-5.2 vs Claude Opus 4.5 vs Gemini 3 Ultimate Showdown: Claude Opus 4.5 leads coding accuracy (80.9% SWE-bench), GPT-5.2 wins mathematical reasoning (100% AIME), and Gemini 3 Pro offers the best value with its 1M token context window. For pure coding tasks, Claude edges ahead. For complex reasoning and math-heavy development, GPT-5.2 shines. For budget-conscious developers, Gemini 3 Flash at $0.50/1M tokens is unbeatable. The real question isn’t “which is best?” but “which fits your workflow?”
All three models now exceed 75% on SWE-bench Verified, a benchmark that seemed impossible 18 months ago. The differences are narrowing, making ecosystem, pricing, and tooling matter more than ever. Check our Claude Code review and AI agents comparison for implementation guidance.
⚡ TL;DR – The Bottom Line
🏆 Best for Coding: Claude Opus 4.5 leads with 80.9% SWE-bench Verified and 59.3% Terminal-Bench scores.
🧠 Best for Math/Reasoning: GPT-5.2 achieves 100% on AIME 2025 and 54.2% on ARC-AGI-2.
🎨 Best for Frontend: Gemini 3 Pro dominates WebDev Arena with 1487 Elo and 1M token context.
💰 Best Value: Gemini 3 Flash at $0.50/1M tokens (10M token project = ~$30).
⚠️ The catch: No single model wins everything. Smart developers use multiple models strategically for different tasks.
📑 Quick Navigation
📊 The Benchmark Showdown: Real Numbers (January 2026)
December 2025 delivered an unprecedented wave of AI coding models. Within three weeks, Anthropic launched Claude Opus 4.5 (November 25), Google released Gemini 3 Pro, and OpenAI unveiled GPT-5.2 (December 19) amid reports of an internal “code red” memo acknowledging competitive pressure.
Here’s where each model stands on the benchmarks that actually matter for developers:
| Benchmark | Claude Opus 4.5 | GPT-5.2 | Gemini 3 Pro | What It Measures |
|---|---|---|---|---|
| SWE-bench Verified | 80.9% 🏆 | 80.0% | 76.2% | Real GitHub bug fixing |
| SWE-bench Pro | N/A | 56.4% 🏆 | N/A | Multi-language (4 languages) |
| Terminal-Bench 2.0 | 59.3% 🏆 | ~47.6% | 54.2% | CLI operations |
| WebDev Arena | N/A | N/A | 1487 Elo 🏆 | Frontend development |
| AIME 2025 (Math) | ~93% | 100% 🏆 | 100% (with tools) | Mathematical reasoning |
| ARC-AGI-2 | 37.6% | 54.2% 🏆 | 45.1% | Abstract pattern recognition |
| GPQA Diamond | 87% | 93.2% | 93.8% 🏆 | PhD-level science |
💡 Swipe left to see all columns →
Key Insight: Claude Opus 4.5 became the first AI model to break 80% on SWE-bench Verified. This isn’t a marginal improvement, it’s a 3-5 percentage point lead on real-world GitHub bug fixing. But GPT-5.2 counters with superior abstract reasoning (ARC-AGI-2) and perfect mathematical scores.
📊 SWE-bench Verified Scores Comparison
💻 Coding Benchmarks: Who Actually Wins?
SWE-bench Verified is the gold standard for AI coding evaluation. It uses real GitHub issues where the model must produce patches that pass actual test suites. No synthetic problems, no hand-picked examples.
Claude Opus 4.5: The Coding Champion
Claude Opus 4.5’s 80.9% score represents genuine breakthrough territory. Here’s what makes it special:
- Terminal proficiency: 59.3% on Terminal-Bench (12 points above GPT-5.2)
- Multi-language consistency: Leads on 7 of 8 languages in SWE-bench Multilingual
- Token efficiency: Uses 76% fewer output tokens than previous versions at equivalent quality
- Security: Industry-leading 4.7% prompt injection success rate (vs GPT’s 21.9%)
🔍 REALITY CHECK
Marketing Claims: “Best AI model for coding, period.”
Actual Experience: Claude excels at understanding codebases holistically and maintaining context across complex refactoring. However, independent testing shows it can be verbose, sometimes generating 2x more code than necessary. One developer noted: “Claude’s architectural thinking is excellent, but it over-engineers simple tasks.”
✅ Verdict: Best for complex, multi-file projects. May overkill simple scripts.
GPT-5.2 Codex: The Reliable Workhorse
GPT-5.2 closes the gap significantly with 80.0% SWE-bench, and dominates on the newer SWE-bench Pro (56.4%) that tests across four programming languages instead of just Python.
- Convention-following code: Produces patterns junior developers can understand and modify
- Speed advantage: Typically completes tasks in 5-15 minutes vs Claude’s 7-20+ minutes
- Lower token consumption: Uses roughly 90% fewer tokens than Claude for equivalent tasks
- Ecosystem: 18,000+ integrated apps, deepest VS Code integration
Gemini 3 Pro: The Frontend Specialist
Gemini 3 Pro takes a different approach with its 1487 Elo score on WebDev Arena. Google calls it their best “vibe coding” model, generating rich, interactive web interfaces from simple prompts.
- UI generation: Creates functional interfaces, not just code snippets
- Multimodal: Native video, audio, and image processing
- Context window: 1M tokens input, the largest of the three
- Budget-friendly: Gemini 3 Flash at $0.50/1M input tokens
For deeper analysis of how these models perform in actual coding tools, see our Cursor 2.0 review and GitHub Copilot Pro+ review.
🧠 Reasoning & Math: The GPT-5.2 Advantage
Where GPT-5.2 truly shines is abstract reasoning and mathematical problem-solving, skills that translate directly to algorithm design, data science, and computational logic.
AIME 2025: GPT-5.2 achieved a perfect 100% score without tools. Claude Opus 4.5 scores approximately 93%. This gap matters for developers working on optimization algorithms, numerical computing, or anything involving complex mathematical foundations.
ARC-AGI-2: GPT-5.2’s 54.2% versus Claude’s 37.6% represents a massive 16.6 percentage point advantage on abstract pattern recognition. This benchmark tests reasoning ability that resists memorization, indicating genuine problem-solving capability.
🔍 REALITY CHECK
Marketing Claims: “GPT-5.2 Thinking is the best model for real-world, professional use.”
Actual Experience: The reasoning advantage is real but comes with trade-offs. GPT-5.2’s “extended thinking” mode can take 7-20+ minutes for complex problems. One developer reported: “Occasional reasoning loops where it thinks for a very long time and then still fails, which is extremely annoying and wastes time.”
✅ Verdict: Superior for math-heavy tasks. Watch for overthinking on simple problems.
💰 Pricing Breakdown: What You’ll Actually Pay
Pricing has shifted dramatically. Claude Opus 4.5 saw a 67% price reduction from previous Opus versions, while Gemini 3 Flash emerged as the budget king.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | 10M Token Project Cost | Context Window |
|---|---|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 | ~$250 | 200K (1M beta) |
| GPT-5.2 | $1.25 | $10-14 | ~$140 | 400K input, 128K output |
| Gemini 3 Pro | $2.00 | $12.00 | ~$120 | 1M input, 64K output |
| Gemini 3 Flash 🏆 | $0.50 | $3.00 | ~$30 | 1M input, 64K output |
💡 Swipe left to see all columns →
🎯 AI Model Capabilities Comparison
The Hidden Cost Factor: Token Efficiency
Raw pricing doesn’t tell the full story. Claude Opus 4.5’s token efficiency can result in lower actual costs for certain task types. At medium effort, it matches previous Sonnet performance while using 76% fewer tokens.
GPT-5.2 consistently uses fewer tokens, with one test showing 90% fewer tokens than Claude for equivalent algorithm tasks. For high-volume usage, this efficiency advantage compounds significantly.
Consumer Plans Comparison
For individual developers using consumer interfaces rather than APIs:
- Claude Pro: $20/month (usage limits apply)
- ChatGPT Plus: $20/month
- Google AI Pro: $19.99/month
- Free Alternative: Google Antigravity offers free Claude Opus 4.5 access during preview
📚 Context Windows: Size Actually Matters

Context window determines how much code, documentation, and conversation history the model can process simultaneously. For large codebases, this is critical.
- GPT-5.2: 400K input tokens, 128K output. Uses “compaction” to summarize earlier context automatically.
- Claude Opus 4.5: 200K standard, 1M beta available. Excels at maintaining context across 30+ hour autonomous operations.
- Gemini 3 Pro: 1M input, 64K output. Largest input window, ideal for processing entire codebases or research papers.
Practical Translation: GPT-5.2’s 400K context is roughly 300,000 words, enough for most entire project documentation. Gemini’s 1M context can handle multiple complete books or massive monorepos.
🔧 Real-World Testing: Beyond Benchmarks
Benchmarks measure specific capabilities, but real-world coding involves architecture decisions, code style, and integration with existing systems. Independent developers have shared detailed comparisons.
Production Feature Build Test
One developer tested all three models on building production features in a 50K+ line Next.js application:
- Claude Opus 4.5: “Most consistent overall. Shipped working results for both tasks, UI polish was the best. Main downside is cost.”
- GPT-5.2 High: “Great code quality and structure, but needed more patience. Slower due to higher reasoning.”
- Gemini 3 Pro: “Most efficient. Both tasks worked, but output often felt like minimum viable version.”
Code Quality Analysis (Sonar Research)
Sonar’s December 2025 analysis of code quality across models revealed:
- Opus 4.5 Thinking: 83.62% pass rate, highest functional performance, but 639K lines of code generated (most verbose)
- Gemini 3 Pro: 81.72% pass rate with low verbosity. Efficiency outlier but highest issue density
- GPT-5.2 High: 80.66% pass rate. Lowest control flow errors (22 per MLOC vs Gemini’s 200)
🔍 REALITY CHECK
Marketing Claims: “These models can replace developers.”
Actual Experience: Even the best models require human oversight. Independent benchmarks show 60% overall accuracy on complex tasks, dropping to just 16% on hard Terminal-Bench problems. One developer summarized: “You’re in reviewer mode more often than coding mode.”
✅ Verdict: Powerful assistants, not replacements. Expect to review and iterate.
👨💻 Developer Experience: What Users Actually Say
Claude Opus 4.5 Sentiment
Community feedback emphasizes reliability and architectural thinking:
“For deeper refactors and test design, Claude 4.5 felt steadier.”
“Claude Code, imo, is still way ahead in terms of tooling. Skills, workflows, agent customization.”
GPT-5.2 Sentiment
Developers appreciate consistency and ecosystem integration:
“For quick questions and everyday tasks, GPT is my go-to. When I need deep reasoning, I use Pro mode.”
“GPT-5.2 produces code that follows common conventions, making it easier for junior developers to understand.”
Gemini 3 Pro Sentiment
Frontend developers particularly appreciate the visual capabilities:
“Clearly a tier 1 LLM for vibe-coding abilities.” — Andrej Karpathy
“Strong for UI and frontend tasks, leveraging visual understanding well.”
For more community insights, see our Claude Opus 4.5 vs Gemini 3.0 detailed comparison.
🎯 When to Choose Each Model
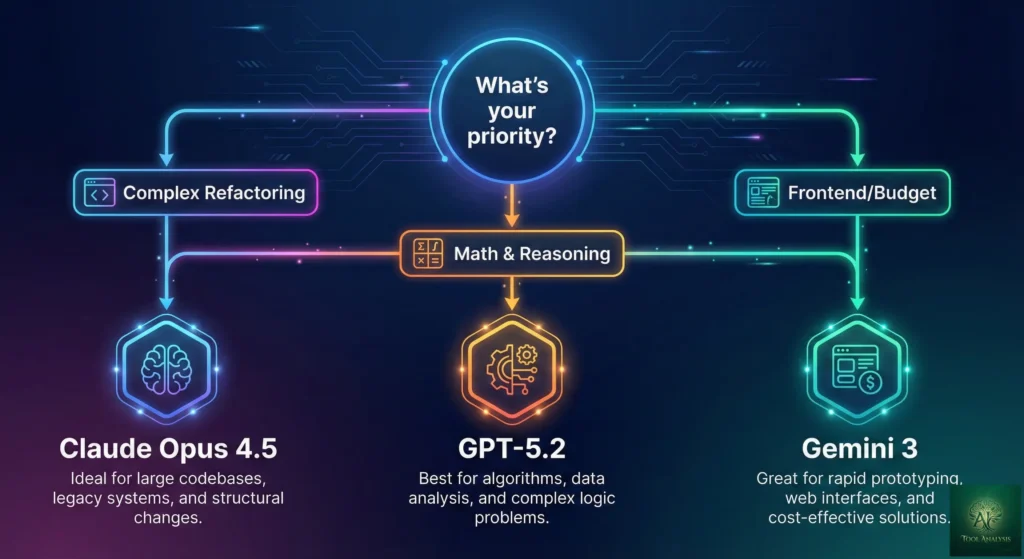
Choose Claude Opus 4.5 If:
- You work on complex, multi-file refactoring projects
- Terminal/CLI proficiency matters (59.3% vs GPT’s 47.6%)
- Security and prompt injection resistance are priorities (4.7% attack success rate)
- You need reliable 30+ hour autonomous operations
- You value architectural thinking over speed
Choose GPT-5.2 If:
- Mathematical reasoning is critical (100% AIME, 54% ARC-AGI)
- You need faster iteration cycles (5-15 min vs 7-20+ min)
- Token efficiency and predictable costs matter
- You’re deeply integrated in the OpenAI/ChatGPT ecosystem
- Your team includes junior developers who need conventional code patterns
Choose Gemini 3 Pro If:
- Frontend/UI development is your primary focus (1487 Elo WebDev Arena)
- You need massive context (1M tokens)
- Budget is a primary concern (Gemini 3 Flash at $0.50/1M)
- You work with multimodal content (video, images, audio)
- Google Workspace integration matters
For free access to Claude Opus 4.5, check Google Antigravity during its preview period.
🔌 Tools & IDE Integration
Model choice often depends on which coding tools you use:
| Tool | Claude Models | GPT Models | Gemini Models | Best For |
|---|---|---|---|---|
| Claude Code | ✅ Native | ❌ | ❌ | Terminal workflows |
| Cursor | ✅ | ✅ | ✅ | GUI + parallel agents |
| GitHub Copilot Pro+ | ✅ Opus 4.5 | ✅ GPT-5 | ✅ Gemini 3 | Multi-model access |
| Windsurf | ✅ Sonnet | ✅ | ✅ | Budget-friendly |
| Antigravity | ✅ Opus 4.5 (free) | ❌ | ✅ Native | Agent-first, free tier |
💡 Swipe left to see all columns →
Pro Tip: Many developers use multiple models. Quick syntax questions with GPT, architectural planning with Claude, and UI generation with Gemini. GitHub Copilot Pro+ at $39/month provides all three in one subscription.
❓ FAQs: Your Questions Answered
Q: Is Claude Opus 4.5 better than GPT-5.2 for coding?
A: Claude Opus 4.5 leads on SWE-bench Verified (80.9% vs 80.0%) and Terminal-Bench (59.3% vs 47.6%), making it technically superior for real-world bug fixing and CLI operations. However, GPT-5.2 excels at mathematical reasoning (100% vs 93% on AIME) and produces more conventional code patterns. Choose Claude for complex refactoring, GPT for math-heavy development.
Q: Which AI coding model is cheapest?
A: Gemini 3 Flash at $0.50 input and $3.00 output per million tokens is the cheapest option. A 10M token project costs approximately $30 with Flash versus $140 with GPT-5.2 or $250 with Claude Opus 4.5. Google Antigravity also offers free Claude Opus 4.5 access during preview.
Q: Can these AI models replace human developers?
A: No. Even at 80%+ SWE-bench accuracy, these models require human oversight. Independent benchmarks show 60% overall accuracy on complex tasks, dropping to just 16% on hard problems. They’re powerful assistants that handle 25-50% of routine coding work while developers focus on architecture, design decisions, and complex problem-solving.
Q: Which model has the largest context window?
A: Gemini 3 Pro offers 1 million input tokens, the largest context window. GPT-5.2 provides 400K input tokens with 128K output. Claude Opus 4.5 has 200K standard with a 1M beta version available.
Q: How do I access Claude Opus 4.5 for free?
A: Google Antigravity offers free access to Claude Opus 4.5 during its public preview period. You can also use Claude’s free tier with limited messages, or GitHub Copilot Pro+ ($39/month) which includes all three models.
Q: Which model is best for frontend development?
A: Gemini 3 Pro leads frontend development with a 1487 Elo score on WebDev Arena. Google calls it their best “vibe coding” model for generating interactive web interfaces.
Q: What is SWE-bench Verified?
A: SWE-bench Verified uses 500 real GitHub issues to test whether AI models can implement valid code fixes. The model receives a repository and issue description, then must produce a patch that passes the test suite. It’s considered the gold standard for AI coding evaluation.
Q: Should I use multiple AI coding models?
A: Yes, many developers adopt multi-model strategies. Quick syntax with GPT, architecture with Claude, UI with Gemini. GitHub Copilot Pro+ ($39/month) provides access to all three in one subscription.
✅ Final Verdict: Which AI Coding Model Wins in 2026?

There’s no single winner. The GPT-5.2 vs Claude Opus 4.5 vs Gemini 3 debate isn’t about finding the “best” model. It’s about matching capabilities to your workflow.
The Bottom Line for Each Model:
Claude Opus 4.5: Best for complex, multi-file projects requiring deep codebase understanding. Superior terminal proficiency and security. Premium pricing but token-efficient for the right tasks.
GPT-5.2: Best for mathematical reasoning, algorithm design, and teams needing conventional code patterns. Largest ecosystem with 18,000+ integrated apps. Faster iteration cycles.
Gemini 3 Pro: Best for frontend development and multimodal projects. Budget-friendly with the largest context window. Strong value with Google Workspace integration.
My Recommendation:
Start with Google Antigravity (free Claude Opus 4.5) to test the highest accuracy model at no cost. If you hit rate limits or need production stability, GitHub Copilot Pro+ ($39/month) provides all three models in one subscription, letting you use the right tool for each task.
The developers who thrive in 2026 won’t be those who pick one model. They’ll be those who master using multiple models strategically.
Stay Updated on AI Coding Tools
Don’t miss the next major model launch. Get weekly reviews of coding assistants, APIs, and AI development platforms delivered every Thursday at 9 AM EST.
- ✅ Honest testing: We actually use these tools, not just read press releases
- ✅ Price tracking: Know when tools drop prices or add free tiers
- ✅ Benchmark updates: New SWE-bench and performance data within days
- ✅ Tool comparisons: Side-by-side analysis like this post weekly
- ✅ Community insights: What Reddit and developers are actually saying
Free, unsubscribe anytime
Related Reading
- Claude Code Review 2026: The Reality After Claude Opus 4.5 Release
- Claude Opus 4.5 vs Gemini 3.0: Head-to-Head Review
- Top AI Agents For Developers 2026: 8 Tools Tested
- GitHub Copilot Pro+ Review: Is $39/Month Worth It?
- Google Antigravity Review: Free Claude Opus 4.5 Access
- Cursor 2.0 Review: $9.9B AI Code Editor Tested
- Gemini 3 Review: Google Finally Delivers
- Antigravity vs Cursor: Google’s AI IDE Tested
Last Updated: January 23, 2026
Models Compared: Claude Opus 4.5, GPT-5.2, Gemini 3 Pro
Next Review Update: When new major model releases or benchmark updates occur
Have a tool you want us to review? Suggest it here | Questions? Contact us