

This DeepSeek review tests the May 2026 reality of the Chinese AI lab that turned the global reasoning-model conversation upside-down in January 2025 and somehow still leads on price-per-quality 18 months later. The brand has two flagship products today — V4 for general chat, R1 (specifically the R1-0528 upgrade) for reasoning — and an opaque-but-real path toward R2 that has slipped due to chip supply constraints. This rebuild covers both products in their current state, the R2 delay story that explains why R1 still matters, the privacy and data-sovereignty questions that still divide Western buyers, and the honest verdict on which DeepSeek product you actually want.
I’ve used DeepSeek continuously since the original R1 launch — on the hosted API for production workloads, on the free chat interface for casual queries, and as a self-hosted open-weight model in one project. The original 2025 version of this review was R1-only and anchored to the “$6 Million Sputnik Moment” hook from that January 2025 launch. This 2026 rebuild repositions the post as DeepSeek’s brand-level canonical: V4 gets the brief overview (with handoff to our full DeepSeek vs ChatGPT comparison), and R1 gets the primary depth because it remains the most interesting and most-tested DeepSeek surface.
⚡ TL;DR – The Bottom Line
What This Is: May 30, 2026 brand-level review of DeepSeek — V4 chat flagship (cheap chat) + R1 / R1-0528 reasoning flagship (cheap reasoning) + open-weight self-hostable variants. Slug renamed from /deepseek-r1-review/ to evergreen /deepseek-review/.
Best For: Cost-sensitive AI workloads at scale, reasoning-heavy production tasks (math/coding/logic), sovereignty-flexible deployments via open-weight self-host, and anyone whose use case is unbothered by Chinese data sovereignty.
Pricing: Hosted chat FREE on deepseek.com. V4 API ~$0.14-$1 per 1M input tokens (5-10x cheaper than GPT-5). R1 API ~$0.55-$2.19 per 1M tokens (roughly 1/18 the cost of o3). Open-weight variants free for self-hosting.
Our Take: V4 = best free chat model when data sovereignty doesn’t matter. R1 = best reasoning-quality-per-dollar deal available anywhere — approaching o3 at 1/18 the price. The “$6M Sputnik” framing was overhyped but the underlying product story held up.
⚠️ The Catch: Hosted DeepSeek sits on Chinese infrastructure subject to Chinese law + content censorship on politically sensitive topics. For regulated business data, use third-party Western hosting of the open-weight variant instead.
📑 Quick Navigation
The Bottom Line (May 2026)
The honest DeepSeek review verdict in May 2026: use V4 when you want a general-purpose chat model at the lowest API price on the market (5-10x cheaper than GPT, 3-5x cheaper than Claude); use R1 when you have a reasoning-heavy workload — math, complex coding, multi-step logic, formal verification — where you’d otherwise reach for OpenAI o3 or Gemini 2.5 Pro and you want comparable quality at roughly 1/18 the API price. The free hosted chat at deepseek.com is the strongest no-cost general-purpose AI chatbot available, with the obvious caveat that your inputs sit on Chinese infrastructure subject to Chinese law. For personal use, this is unlikely to matter. For regulated business data, audit compliance before adopting hosted DeepSeek, or self-host the open-weight variants on your own infrastructure.
🧠 The DeepSeek Product Line (May 2026)
The DeepSeek review framing that actually helps in May 2026: DeepSeek is three things, not one. Most coverage conflates them, which is part of why the brand can feel confusing if you’ve only read one article.
- DeepSeek V4 — the general-purpose chat flagship. Successor to V3.2 (which itself succeeded V3). Competes with GPT-5.4/5.5 and Claude Sonnet 4.6 on day-to-day chat workloads. Free on deepseek.com. On the API, roughly $0.14-$1 per million input tokens — 5-10x cheaper than GPT-5 and 3-5x cheaper than Claude Sonnet 4.6. For the full V4 vs GPT-5.x deep-dive see our DeepSeek vs ChatGPT comparison.
- DeepSeek R1 / R1-0528 — the reasoning model. Built to compete with OpenAI’s o-series (o1, o3) and Gemini 2.5 Pro on math, complex coding, formal logic, and multi-step problem solving. R1-0528 (May 2025 upgrade) is the current build. On the API, dramatically cheaper than o3 (roughly 1/18 the per-token price) while approaching its quality on hard reasoning benchmarks.
- Open-weight variants — DeepSeek releases open-weight models for both V-series and R-series that you can self-host on your own infrastructure. The variants are not exactly the same as the hosted flagship models (the hosted versions usually have additional fine-tuning), but they’re close enough for most use cases. Useful for sovereignty-sensitive deployments where the hosted Chinese-infrastructure question is a deal-breaker.
The brand-level question — “should I use DeepSeek?” — depends entirely on which of the three you mean. V4 is the general chat answer; R1 is the reasoning answer; open-weight is the sovereignty answer. They’re complements, not competitors.
⏱️ What Just Happened (DeepSeek’s 2025-2026 Trajectory)
The original version of this DeepSeek review was R1-focused and frozen in the January 2025 “$6 Million Sputnik Moment” hook — when DeepSeek’s claimed ~$6M training cost for R1 triggered a $600B Nvidia stock crash on January 27, 2025 and a global panic about whether US AI dominance was real. The May 2026 picture is calmer, more substantive, and more interesting:
- V3 → V3.2 → V4 (chat flagship lineage). V3 launched late 2024, V3.2 in 2025, V4 in early 2026. Each iteration tightened the gap with GPT and Claude on general chat. V4 is genuinely competitive with GPT-5.4 and Claude Sonnet 4.6 on most chat workloads.
- R1 → R1-0528 (reasoning flagship lineage). R1 launched January 2025 with the Sputnik moment. R1-0528 shipped in May 2025 as an upgrade that meaningfully improved reasoning quality. R1-0528 is the current build and remains the only DeepSeek reasoning model in production.
- R2 was widely expected for Q1 2026 — and has slipped. DeepSeek pivoted to using Huawei Ascend chips for inference (encouraged by Chinese authorities) while keeping Nvidia chips for training. The Ascend stability issues, slower inter-chip connectivity, and inferior software have delayed R2’s release. As of May 2026, no firm R2 launch date has been announced; some analyst forecasts have slipped R2 into Q3 or Q4 2026.
- R1 vs OpenAI o3 on AIME 2024: R1 scored 79.8% vs o3’s 83.3% on the 2024 American Invitational Mathematics Examination — a 3.5-point gap on a hard reasoning benchmark, with R1 at roughly 1/18 the per-token API price. The price-per-quality math is the strongest argument for R1 in May 2026, especially for high-volume reasoning workloads where the cost gap compounds.
- R1 vs Gemini 2.5 Pro and o3: R1-0528 performance approaches both leading reasoning models on math, programming, and general logic. The gap is real but smaller than the headline framing suggests.
- Open-weight ecosystem strengthened. Self-hosting R1 on your own GPUs is mature and well-documented as of mid-2026. Vendors like Together AI, Fireworks, and DeepInfra host R1 variants if you want third-party hosting without going through DeepSeek’s own infrastructure.
- Privacy/sovereignty story unchanged. Hosted DeepSeek (deepseek.com chat and the official API) runs on Chinese infrastructure subject to Chinese law. The Western enterprise buyer concern is identical to what it was in January 2025; the answer for sovereignty-sensitive deployments is still “self-host the open-weight variant or use a third-party Western host.”
The single most important change for the DeepSeek review verdict is the R2 delay. If R2 had shipped on its expected Q1 2026 timeline, R1 would be a legacy product today and the rebuild would be a retirement. Instead, R1-0528 remains DeepSeek’s current reasoning flagship and continues to deliver competitive quality at price points the US labs can’t touch on reasoning workloads.
⚠️ Reality Check: The “$6 Million Sputnik Moment” Framing Was Always Misleading
The January 2025 narrative that DeepSeek trained R1 for $6M while OpenAI spent billions was the hook that triggered Nvidia’s $600B single-day stock crash. The real picture is more nuanced — the $6M figure covers the final training run only, not the prior infrastructure investment, prior model checkpoints, or R&D capacity. The actual all-in cost is almost certainly higher, but the per-token inference cost is genuinely low and the open-weight release verifies the model exists at the claimed quality. The headline was overhyped; the underlying product story was real. Lead with the product story, not the price-shock framing, when evaluating DeepSeek today.
💬 DeepSeek V4 (Chat Flagship — Brief Overview)
V4 is DeepSeek’s general-purpose chat model. Released early 2026 as the V3.2 successor. For day-to-day chat workloads — drafting, summarizing, Q&A, casual coding help, content generation — V4 is genuinely competitive with GPT-5.4/5.5 and Claude Sonnet 4.6. It’s not the absolute quality leader; on the hardest reasoning tasks GPT-5.5 and Claude Opus 4.7 still edge ahead. But on the typical workload distribution, V4 is comparable to flagship chat models at a fraction of the API cost.
For the full V4 vs GPT-5.x comparison — including coding tests, real pricing math at typical workload tiers, the data-sovereignty decision tree, and which to default to for which use case — see our dedicated DeepSeek vs ChatGPT review. This DeepSeek brand review covers V4 briefly because the comparison post handles it in depth.
🧮 DeepSeek R1 / R1-0528 (Reasoning Flagship — Primary Depth)
R1 is the model that put DeepSeek on the global map in January 2025 and remains the brand’s most differentiated product 18 months later. The R1-0528 upgrade shipped in May 2025 and has been the stable build through May 2026 — DeepSeek has held off on a major R-series version bump while waiting for R2 to be ready. The interesting consequence: R1-0528 has had a full year to mature in production, which is unusual for AI flagships and a real strength when you need stability.
How R1 Reasoning Actually Works
R1 was built around the same “test-time compute” idea as OpenAI’s o-series — the model spends extra inference time “thinking” through a problem before producing an answer, expanding the visible reasoning trace as it works. You can watch R1 think on screen, which is genuinely useful for debugging when the model gets something wrong. The visible reasoning isn’t just a UI nicety; it’s a debuggability feature that o3 doesn’t fully match.
R1’s training approach used reinforcement learning from human feedback combined with a chain-of-thought objective that explicitly rewarded long, structured reasoning. The training cost figures DeepSeek cited at launch (~$6M) generated significant skepticism — the real cost is almost certainly higher when you account for prior infrastructure investment, but R1’s per-token inference cost is genuinely low and the open-weight release verifies the model exists at the claimed quality.
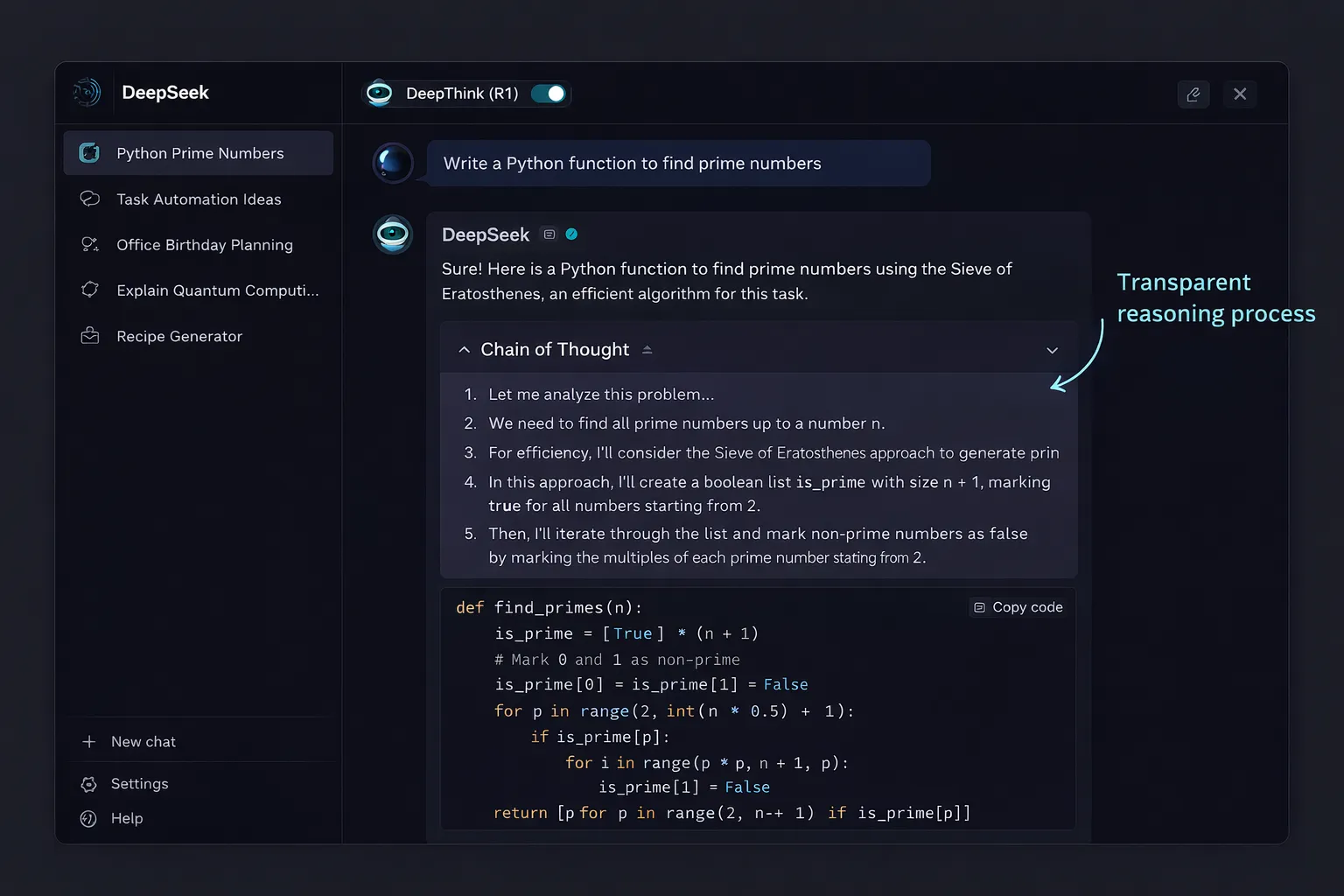
When R1 Is Worth Reaching For
- Math-heavy workloads. 79.8% on AIME 2024 versus o3’s 83.3% — a 3.5-point gap. For tutoring, automated grading, math research assistance, formal proof drafting, R1 is the price-leader and the quality is in the same league.
- Complex coding tasks. R1 handles multi-step algorithm design, formal verification, and “explain why this code is wrong” tasks at near-o3 quality. For routine code completion, V4 or GPT-4o is fine and cheaper still; R1 earns its keep on the hard problems.
- Multi-step logic and planning. The visible chain-of-thought lets you debug planning failures, which matters for any production workload that involves an agent making sequential decisions.
- High-volume reasoning at scale. If you’re running thousands or millions of reasoning queries per month, the 1/18 price gap versus o3 compounds into real budget impact.
When To Skip R1
- Casual chat workloads. R1’s reasoning overhead makes it slower than V4 for general Q&A. Use V4 for chat, R1 for reasoning.
- Hard creative writing. R1’s chain-of-thought style produces structured prose, which can read mechanical for narrative or persuasive writing. Claude Sonnet 4.6 or GPT-5.5 are stronger here.
- Regulated business data on the hosted API. If data sovereignty rules out Chinese-hosted infrastructure, use the open-weight R1 variant via self-hosting or a Western third-party host.
- Latency-sensitive workloads. R1 takes meaningfully longer than V4 because of the chain-of-thought expansion. For real-time chat UX, V4 or a non-reasoning chat model is the right pick.
⚔️ R1 vs OpenAI o3 vs Gemini 2.5 Pro (May 2026)
The cleanest competitive frame for the DeepSeek review reasoning question: R1 vs o3 vs Gemini 2.5 Pro. These are the three leading reasoning flagships as of May 2026, and the trade-offs split along familiar lines — o3 leads on quality, R1 leads on price-per-quality, Gemini 2.5 Pro leads on integrated multimodal reasoning.
| Dimension | DeepSeek R1 / R1-0528 | OpenAI o3 | Gemini 2.5 Pro |
|---|---|---|---|
| AIME 2024 accuracy | 79.8% | 83.3%+3.5pt | Comparable to o3 |
| ARC-AGI | Strong, not best-in-class | 96.7% (current leader)LEADER | Strong, behind o3 |
| API price (per 1M input tokens) | ~$0.55CHEAPEST | ~$10 | ~$1.25 |
| API price relative to o3 | ~1/18PRICE LEADER | baseline | ~1/8 |
| Visible chain-of-thought | Yes, full traceDEBUGGABLE | Hidden by default | Partial |
| Open-weight variant | Yes (self-host or third-party)SOVEREIGNTY | No | No |
| Data sovereignty | Chinese (hosted); flexible (self-host)FRICTION | US | US |
| Latency | Moderate | Slower (longer reasoning) | Moderate |
| Best for | Price-sensitive reasoning at scale | Maximum reasoning quality | Multimodal reasoning |
The right call depends on workload composition. If reasoning quality is the only thing that matters and budget is unbounded, o3. If you’re running thousands of reasoning queries per day at production scale and the cost ratio compounds, R1. If your reasoning workload is multimodal (images + text together), Gemini 2.5 Pro. Many sophisticated teams use two of the three for different workload types, exactly like the chat flagship landscape.
📊 Reasoning Model Benchmark: R1 vs o3 vs Gemini 2.5 Pro (May 2026)
AIME 2024 math accuracy + ARC-AGI scores. Higher is better.
💰 DeepSeek Pricing (May 2026)
The DeepSeek review pricing picture is the cleanest part of the whole product story. Free for casual hosted use. Low per-token API pricing for production. Open-weight free for self-hosting (your costs are GPU/ops). No paid consumer tier — DeepSeek hasn’t built a $20/month Plus equivalent because the chat is already free.
| Surface | Price (May 2026) | What You Get |
|---|---|---|
| Hosted chat (deepseek.com) | Free | V4 chat + R1 reasoning toggle, unlimited queries with rate limits, web search groundingSTRONGEST FREE |
| API: V4 input | ~$0.14 per 1M (cached) / ~$0.27 (uncached) | 5-10x cheaper than GPT-5 on chat workloadsPRICE LEAD |
| API: V4 output | ~$1.10 per 1M tokens | Same gap, sometimes wider |
| API: R1 input | ~$0.55 per 1M tokens | Roughly 1/18 the per-token cost of o3VS o3 |
| API: R1 output | ~$2.19 per 1M tokens | Includes the reasoning trace tokens |
| Open-weight self-host | Free (model weights); pay GPU costs | Sovereignty-friendly deployment; ops complexity is realSOVEREIGNTY |
| Third-party hosting | Vendor-specific (10-20% premium) | Western infrastructure, no Chinese routingMIDDLE PATH |
Two pricing observations matter for the DeepSeek review buying decision. First: the hosted chat at deepseek.com is the strongest no-cost general AI chat tool on the market, period — V4 quality is comparable to ChatGPT free GPT-5, and R1 reasoning is available with no subscription, which no Western model offers at this quality level. Second: at production API scale, DeepSeek’s pricing gap compounds. A workload that costs $5,000/month on OpenAI’s API can drop to $300-$500/month on DeepSeek’s V4, or $400-$700/month on R1 versus o3 — meaningful budget impact for any company running real volume.
📊 API Price Comparison (USD per 1M tokens, May 2026)
Lower is better. DeepSeek’s structural pricing advantage compounds at production scale.
🛡️ Privacy & Data Sovereignty (The Decision That Actually Matters For Many Buyers)
The DeepSeek review sovereignty question that decides whether DeepSeek is appropriate for many Western enterprise buyers: where does the data go, and which jurisdiction’s laws apply? The honest answer requires unpacking three deployment paths separately, because they have meaningfully different sovereignty profiles.
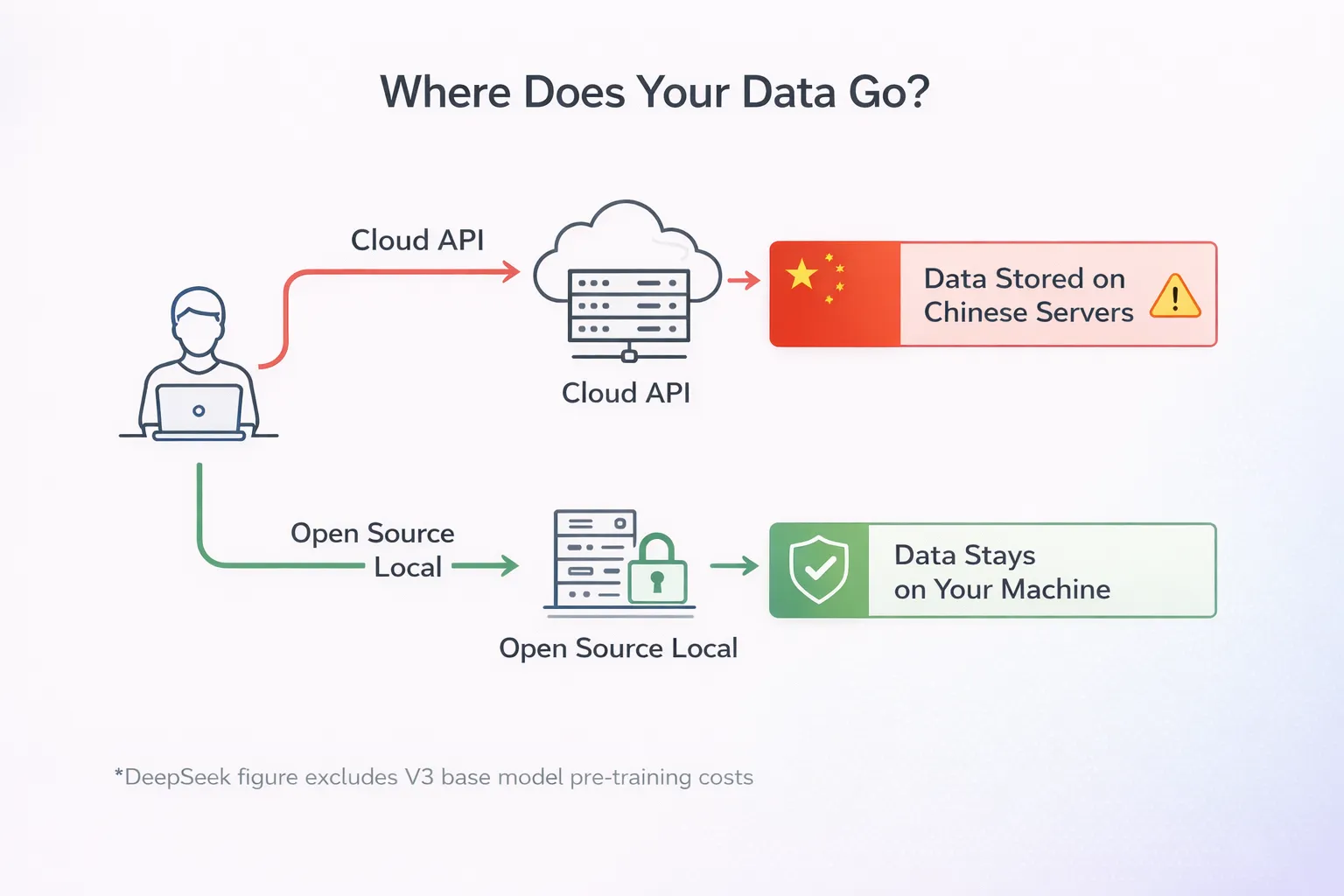
- Hosted chat (deepseek.com) and DeepSeek’s own API. Both run on Chinese infrastructure subject to Chinese law, including the 2017 National Intelligence Law that requires Chinese organizations to support state intelligence work. Your inputs sit on Chinese servers. For personal use, casual research, or non-sensitive workloads, this is unlikely to matter. For regulated industries (healthcare, finance, defense), business confidential data, or anything covered by US/EU data residency requirements, the hosted path is a non-starter without explicit compliance review.
- Open-weight self-hosted DeepSeek. You download the model weights from Hugging Face, run them on your own GPU infrastructure (or your cloud’s), and the data never leaves your environment. This is the sovereignty-friendly path. Trade-off: real ops complexity, real GPU costs, and the model weights are not always exactly identical to the hosted flagship (the open-weight variants typically lack some of the safety/alignment fine-tuning DeepSeek does on hosted versions).
- Third-party Western hosting (Together AI, Fireworks AI, DeepInfra, others). A middle path — they host the open-weight DeepSeek variants on Western infrastructure (US/EU). Your data routes through the third party but never touches Chinese infrastructure. Often 10-20% more expensive than DeepSeek’s own API, still meaningfully cheaper than OpenAI/Anthropic equivalents.
The censorship dimension is a separate but related question. The hosted chat at deepseek.com filters certain politically sensitive topics (Tiananmen, Xinjiang, Taiwan’s status, Chinese leadership criticism) consistent with Chinese internet regulations. The open-weight variants do not have this filter — if you self-host or use a Western third-party host, the censorship filter is gone. For most business use cases, the censorship rarely matters. For research, journalism, or any work touching the filtered topics, the hosted path is clearly inappropriate; the self-hosted path works fine.
⚠️ Reality Check: The “DeepSeek Is Banned For Business” Take Is Wrong (But So Is “It’s Safe For Everything”)
Two equally wrong takes dominate the discourse. The first: DeepSeek is unusable for any business workload because it’s Chinese. The second: data sovereignty is overblown and DeepSeek is fine for any use case. The accurate picture sits between. Hosted DeepSeek (deepseek.com and the official API) is genuinely inappropriate for regulated business data because the infrastructure sits in China. Open-weight self-hosted DeepSeek is genuinely fine for sovereignty-sensitive deployments because the data never leaves your infrastructure. Third-party Western hosting (Together AI, Fireworks, DeepInfra) is the practical middle path — Western infrastructure, no Chinese routing, modest cost premium. Match the deployment path to the data sensitivity, not the brand name.
🔮 The R2 Outlook (And Why R1 Still Matters)
R2 was the central question hanging over DeepSeek through early 2026 and has been the central disappointment through mid-2026. Industry expectations were that R2 would ship Q1 2026 with substantial reasoning improvements that would meaningfully close the gap to o3 and Gemini 2.5 Pro. Q1 came and went. Q2 is closing without a release. As of May 30, 2026, no firm R2 launch date has been announced by DeepSeek, and multiple credible reports attribute the delay to chip supply constraints.
The specific story: Chinese authorities encouraged DeepSeek to adopt Huawei’s Ascend chips for AI training to reduce reliance on Nvidia. DeepSeek tested the Ascend chips during R2 training and ran into stability issues — slower inter-chip connectivity, immature software stack, and intermittent failures during long training runs. DeepSeek ultimately pivoted to using Nvidia chips for training (where stability matters most) and Huawei Ascend chips for inference (where intermittent failures are recoverable). The chip-swap process consumed engineering capacity that would otherwise have gone toward R2 finalization, and the result is the delay.
The practical implication for any DeepSeek review reader: R1-0528 remains the current reasoning flagship and is likely to remain so through at least Q3 2026. If your project needs a reasoning model today, R1 is the DeepSeek answer; waiting for R2 is not a sensible strategy on the current timeline. When R2 does ship, expect a benchmark bump, an evergreen URL update on this post, and a fresh comparison against whichever o-series or Gemini reasoning model is leading at that point.
💡 Key Takeaway: The R2 Delay Is The Reason R1 Still Matters In May 2026
If R2 had shipped on its expected Q1 2026 timeline, R1 would be a legacy product today and this DeepSeek review would be a retirement. The delay — caused by DeepSeek’s pivot to Huawei Ascend chips for inference and the resulting stability/software issues — has kept R1-0528 as the current reasoning flagship for 12+ months. The accidental consequence: R1 has had unusually long to mature in production. For teams that value model stability over chasing the newest release, R1’s longevity is a feature, not a bug. For teams waiting for R2 quality, the practical advice is: don’t wait. Build on R1 now, migrate when R2 ships.
🎯 Who Should Use DeepSeek (And Which Product)
Free Hosted Chat — Perfect For:
- Personal users who want a strong free general AI chatbot without subscribing to ChatGPT Plus or Claude Pro.
- Students testing R1 reasoning on math or coding homework where the answer matters more than the platform.
- Researchers exploring DeepSeek capabilities before committing to API integration.
- Anyone whose use case is unbothered by Chinese data sovereignty (personal queries, non-sensitive work).
V4 API — Perfect For:
- Production chat applications where the 5-10x cost gap versus GPT-5 compounds into real budget impact.
- Teams already using OpenAI’s SDK who want to A/B test V4 against GPT-5.4 with minimal migration friction (DeepSeek’s API is OpenAI-compatible).
- Cost-sensitive AI features inside SaaS products — V4 quality is plenty for most “summarize this”, “classify that”, “draft this email” workloads.
- International users outside the US/EU who don’t have data sovereignty concerns.
R1 API — Perfect For:
- High-volume reasoning workloads — math tutoring, formal verification, complex code review, multi-step planning at scale.
- Production applications where o3 quality is desirable but o3 pricing is prohibitive.
- Teams that value the visible chain-of-thought for debugging agent decision failures.
- Research projects needing the open-weight variant for sovereignty or reproducibility reasons.
Skip DeepSeek If:
- Your workload involves regulated business data (healthcare, finance, defense, government) and you need US/EU data residency — use a Western third-party host of the open-weight R1 instead.
- You need absolute maximum reasoning quality and cost is a rounding error — use OpenAI o3 or wait for the next o-series upgrade.
- Your work touches topics the hosted version filters (China geopolitics, certain political topics) and switching to self-hosted ops isn’t viable for your team.
- You require strong creative writing as your primary AI task — Claude Sonnet 4.6 or GPT-5.5 produce stronger first drafts.
🎯 Get Honest AI Model Reviews — Free
DeepSeek R2, GPT-6, Claude Opus 5, Gemini 4 — the flagship LLM space ships major releases monthly. Subscribe for honest reviews, benchmark updates, and verdicts that actually matter for buying decisions.
Subscribe to the Weekly Brief →✅ Final Verdict
The honest DeepSeek review verdict for May 2026: this is a credible flagship AI brand with two genuinely competitive products at price points that no Western lab matches. V4 is the best free general AI chat model on the market when you discount the data sovereignty question; on the API it’s a 5-10x cost saving over GPT-5 for comparable chat quality. R1 / R1-0528 is the best reasoning-quality-per-dollar deal available anywhere — approaching o3 quality at roughly 1/18 the per-token cost — and remains the current DeepSeek reasoning flagship because R2 has been delayed by chip supply constraints.
The DeepSeek brand-level verdict that a typical reader should walk away with: if you don’t care about data sovereignty and you want the cheapest credible flagship AI, hosted DeepSeek (V4 for chat, R1 for reasoning) is the answer. If you do care about data sovereignty, third-party Western hosting of the open-weight variants gives you most of the cost savings with most of the sovereignty benefits, with real ops complexity as the cost. The “$6 Million Sputnik Moment” framing from January 2025 was overhyped at the time and now feels dated — but the underlying product story has held up substantially better than the skeptics predicted, which is the main reason this brand-level review exists at all.
Overall score: 4.5/5 ⭐⭐⭐⭐½ — unchanged from the late-2025 R1-only review. The score holds because R1-0528 has aged better than expected (still the current reasoning flagship 12 months in) and V4 has substantively improved the general chat surface. Half a star off for the data sovereignty question (still a real friction for many buyers), the R2 delay (undermines the brand’s velocity story), and the censorship filter on the hosted version (matters for some use cases even when not for others).
🎥 Watch: DeepSeek R1 Hands-On Walkthrough
Hands-on walkthrough covering R1’s reasoning trace, sample tests, and the privacy/sovereignty implications. Click to play.

❓ Frequently Asked Questions
DeepSeek V4 vs R1: which one do I want?
V4 is the general-purpose chat model — use it for everyday chat, summarization, drafting, casual coding. R1 (specifically R1-0528) is the reasoning model — use it for math, complex coding, formal logic, multi-step planning. The free hosted chat at deepseek.com lets you toggle between them per query. On the API, the choice depends on workload: V4 for high-volume general chat at $0.14-$1 per 1M tokens, R1 for reasoning workloads at ~$0.55-$2.19 per 1M tokens.
Is DeepSeek R1 actually as good as OpenAI o3?
Close but not equal. R1 scored 79.8% on the AIME 2024 math benchmark versus o3’s 83.3% — a 3.5-point gap. On ARC-AGI, o3 leads at 96.7% and R1 trails. On general reasoning workloads, R1 quality is comparable to o3 and Gemini 2.5 Pro for most tasks. R1’s edge is price — roughly 1/18 the per-token cost of o3, which compounds dramatically at production scale.
When is DeepSeek R2 coming?
No firm date as of May 30, 2026. R2 was widely expected for Q1 2026, but DeepSeek’s pivot to Huawei Ascend chips for inference (encouraged by Chinese authorities) ran into stability and software issues that consumed engineering capacity. Multiple analyst forecasts have slipped R2 into Q3-Q4 2026 or later. R1-0528 remains the current reasoning flagship and is likely to stay that way for at least several more months.
Is DeepSeek safe to use for business data?
Depends on the deployment path. Hosted DeepSeek (deepseek.com chat and the official API) runs on Chinese infrastructure subject to Chinese law — for regulated business data, this is a non-starter without explicit compliance review. The open-weight self-hosted variant gives you full data sovereignty at the cost of ops complexity. Third-party Western hosting (Together AI, Fireworks AI, DeepInfra) routes data through US/EU infrastructure and bypasses Chinese routing — a good middle path for sovereignty-sensitive deployments.
Can I run DeepSeek locally?
Yes, with caveats. DeepSeek releases open-weight variants for both V-series and R-series on Hugging Face. R1’s full model requires significant GPU capacity (multi-GPU node) for production inference; smaller distilled variants run on single-GPU setups. Self-hosting gives you full data sovereignty and no censorship filter, but you take on real GPU costs and ops complexity. Most teams who want self-hosting use a managed third-party host instead of running it themselves.
How bad is DeepSeek’s censorship?
On the hosted chat at deepseek.com, certain politically sensitive topics (Tiananmen, Xinjiang, Taiwan’s status, Chinese leadership criticism) are filtered. For most business use cases, this rarely matters in practice. For research, journalism, or any work touching the filtered topics, the hosted path is clearly inappropriate. The open-weight variants do not have the filter — self-hosted DeepSeek (or third-party Western hosting of the open-weight version) gives you uncensored output.
How does DeepSeek pricing compare to OpenAI and Anthropic?
DeepSeek is structurally cheaper on the API across the board. V4 input tokens run roughly 5-10x cheaper than GPT-5 (~$0.14-$0.27 per 1M vs ~$1.50-$3.00). R1 reasoning runs roughly 1/18 the per-token cost of o3. The free hosted chat at deepseek.com has no equivalent in the OpenAI or Anthropic consumer lineup — both companies require Plus/Pro subscriptions to remove free-tier limits. The DeepSeek pricing gap is the brand’s single biggest competitive advantage and the reason cost-sensitive workloads keep adopting it despite the sovereignty friction.
What’s the best alternative to DeepSeek if I want a similar product?
For the chat side, the closest alternatives are open-weight models from Meta (Llama variants), Mistral (Mistral Large), and Qwen (from Alibaba — note: also Chinese-hosted on its official API, similar sovereignty profile). For the reasoning side, the closest open-weight alternatives are limited; o-series and Gemini 2.5 Pro are the main proprietary competitors, and there’s no open-weight reasoning model at R1’s quality level yet. See our broader best AI developer tools guide for the full landscape.
Does DeepSeek have a mobile app?
Yes, DeepSeek has iOS and Android apps for the hosted chat interface. The mobile experience is functional but lags behind the web version on feature parity and stability. For serious workflows, the web interface at deepseek.com or direct API integration is the better path.
✅ Where DeepSeek Wins
- ✓ R1 reasoning at ~1/18 the per-token cost of o3
- ✓ V4 chat at 5-10x cheaper than GPT-5 on API
- ✓ Strongest free hosted AI chat on the market (V4 + R1 toggle)
- ✓ Open-weight variants — self-host for sovereignty
- ✓ OpenAI-compatible API — drop-in migration
- ✓ Visible chain-of-thought in R1 (debuggable)
- ✓ R1-0528 has had 12+ months in production (stability win)
- ✓ Third-party Western hosting available (Together / Fireworks)
❌ Where DeepSeek Falls Short
- ✗ Hosted infrastructure in China — sovereignty friction
- ✗ Content censorship on politically sensitive topics (hosted only)
- ✗ R2 delayed — undermines the velocity story
- ✗ R1 quality trails o3 on hardest reasoning (3.5pt AIME gap)
- ✗ R1 latency higher than V4 (chain-of-thought overhead)
- ✗ Creative writing flatter than Claude / GPT
- ✗ Self-host requires real GPU ops complexity
- ✗ No paid consumer tier (no Plus/Pro equivalent)
Score holds because R1-0528 has aged better than expected (still the current reasoning flagship 12 months in) and V4 has substantively improved the general chat surface. Half a star off for the data sovereignty question, the R2 delay, and the censorship filter on the hosted version.

📚 Related Reading
- DeepSeek vs ChatGPT — full V4 vs GPT-5.4/5.5 comparison with coding tests and data-sovereignty deep-dive
- ChatGPT Review — OpenAI’s flagship covered in depth
- Claude AI Review — Anthropic’s chat flagship
- Gemini Review — Google’s chat + reasoning lineup including Gemini 2.5 Pro
- Perplexity Review — multi-model access tool that includes DeepSeek as one option
- Claude Code Review — for coding workloads where Claude leads
- Best AI Developer Tools — the broader landscape
- The Complete AI Tools Guide — buyer’s guide for 200+ tools
Founder of AI Tool Analysis. Tests every tool personally so you don’t have to. Covering AI tools for 10,000+ professionals since 2025. See how we test →
Stay Updated on Flagship AI Models
The flagship LLM category shifts every month. Subscribe for honest reviews of new DeepSeek / ChatGPT / Claude / Gemini releases, benchmark updates, and pricing changes — delivered every Thursday at 9 AM EST.
- ✅ Honest Reviews: We actually test these models, not rewrite press releases
- ✅ Model Releases: DeepSeek R2 / GPT-6 / Claude Opus 5 covered within days of launch
- ✅ Pricing Changes: Know when API tiers shift
- ✅ Benchmark Updates: AIME, ARC-AGI, MMLU tracking as the field evolves
- ✅ No Hype: Just the AI news that matters for your work
Free, unsubscribe anytime. 10,000+ professionals trust us.
Last Updated: May 30, 2026
Tools Tested: DeepSeek V4 (chat flagship, January 2026 release), DeepSeek R1 / R1-0528 (reasoning flagship, May 2025 build), DeepSeek open-weight variants self-hosted on third-party infrastructure. All pricing verified against api-docs.deepseek.com as of May 30, 2026. Verify current pricing on deepseek.com before publish — DeepSeek occasionally adjusts API tiers.
Slug Note: Renamed from /deepseek-r1-review/ to /deepseek-review/ on May 30, 2026 for evergreen URL. 301 redirect in place. Original version-locked slug retired under the no-version-or-year-in-slugs standing policy.
Next Review Update: August 2026 (or sooner if DeepSeek ships R2, repricing, or major V-series successor)
Have a tool you want us to review? Suggest it here | Questions? Contact us