

🆕 Double Launch Alert (November 2025): The AI landscape just shifted dramatically. Google launched Gemini 3.0 on Nov 18th, followed closely by Anthropic launching Claude Opus 4.5 on Nov 24th. This review compares these brand-new flagship models.
If you thought the AI race was intense before, November 2025 just hit the accelerator. In the span of one week, Google and Anthropic released their most powerful models yet: Gemini 3.0 and Claude Opus 4.5. This isn’t just another incremental update; it marks a fundamental divergence in strategy that defines the state-of-the-art for 2025.
Click any section to jump directly to it
- 🌋 The November 2025 AI Earthquake
- 🔬 Gemini 3.0: Reasoning and Generative UI
- 💻 Claude Opus 4.5: The Engineer’s Choice
- 📊 Head-to-Head: The Benchmark War Decoded
- 👨💻 Real-World Coding Test: Backend vs Frontend
- 🤖 The Agentic Workflow Showdown
- 🧠 Context Windows and Pricing
- 🗣️ Community Verdict: What Developers Are Saying
- 🤔 Who Should Use Which Model?
- ❓ FAQs: Your Questions Answered
- 🏁 Final Verdict: A Multi-Model Future
This Claude 4.5 vs Gemini 3.0 review cuts through the marketing claims—like Salesforce CEO Marc Benioff calling Gemini 3.0 an “insane leap”—to analyze what these models actually do differently. Google is betting big on complex reasoning and revolutionary new ways to interact with AI, while Anthropic is laser-focused on coding excellence and reliable autonomous agents.
{kind=link}
I’ve spent the last few days testing both models rigorously. The results highlight a clear trend: the era of the general-purpose chatbot is ending, and the age of specialized AI is here.
The Bottom Line: Specialization is the New Norm
The key takeaway is that the search for a single “best” AI model is over. Claude 4.5 and Gemini 3.0 excel in distinct areas.
Gemini 3.0 is a breakthrough in complex reasoning, dominating the hardest science and logic benchmarks (93.8% on GPQA Diamond). It introduces “Generative UI” (also called “vibe coding”)—the ability to create interactive interfaces instead of just text—and excels at multimodal understanding (video, audio, images). It’s also significantly cheaper.
Claude Opus 4.5 is the undisputed king of coding. It achieved a record-breaking 80.9% on the SWE-bench (real-world software engineering tasks) and is optimized for reliable, long-running agentic workflows. It’s the model you trust for critical enterprise tasks, building on the reliability we noted in our comprehensive Claude AI review.
Best for Researchers & Innovators: Gemini 3.0.
Best for Engineers & Enterprise
Reliability: Claude Opus 4.5.
🌋 The November 2025 AI Earthquake
The pace of AI development has reached a fever pitch. In November 2025, we witnessed a rapid-fire exchange between the two leading AI labs that redefined the frontier.
November 18th: Google Fires First. Google announced Gemini 3.0, touting a “new era of intelligence.” It immediately showcased unprecedented scores on reasoning benchmarks and introduced “Generative UI.” The launch was integrated into Google Search on day one, signaling massive confidence in the model. As we covered in our AI News coverage, the impact was immediate.
November 24th: Anthropic Responds. Just six days later, Anthropic launched Claude Opus 4.5. Their announcement was laser-focused on practical application, calling it the “best model in the world for coding, agents, and computer use.” Crucially, they also announced a massive 66% price reduction for their flagship model.
This rapid succession of releases signifies a clear shift. The focus is no longer just on raw intelligence; it’s about how that intelligence is applied in specialized workflows.
🔬 Gemini 3.0: Reasoning and Generative UI
Google DeepMind designed Gemini 3.0 to tackle the hardest problems in AI: complex reasoning and true multimodal understanding. It’s built to process text, images, video, and audio simultaneously.
The Reasoning Breakthrough
Gemini 3.0’s most significant achievement is its performance on benchmarks designed to test PhD-level understanding and logic.
- GPQA Diamond: This tests expert knowledge in biology, physics, and chemistry. Gemini 3.0 Pro scored 91.9%. The higher-compute “Deep Think” mode achieved 93.8%, effectively outperforming human experts.
- Humanity’s Last Exam (HLE): A test designed to be “un-gameable,” requiring genuine logic. Gemini 3.0 Deep Think scored 41.0%, significantly higher than competitors.
If your work involves deep scientific analysis or novel problem-solving, Gemini 3.0 is the current state-of-the-art.
Generative UI (“Vibe Coding”): Beyond the Chatbox
Perhaps the most revolutionary feature of Gemini 3.0 is “Generative UI” (GenUI), often referred to by developers as “vibe coding.” This changes how we interact with AI.
Before GenUI: You ask for data analysis, and the AI replies with a paragraph of text.
With GenUI: You ask for data analysis, and the AI builds a custom, interactive mini-application (a widget) directly in the interface. You get buttons, sliders, and dynamic graphs you can manipulate in real-time.
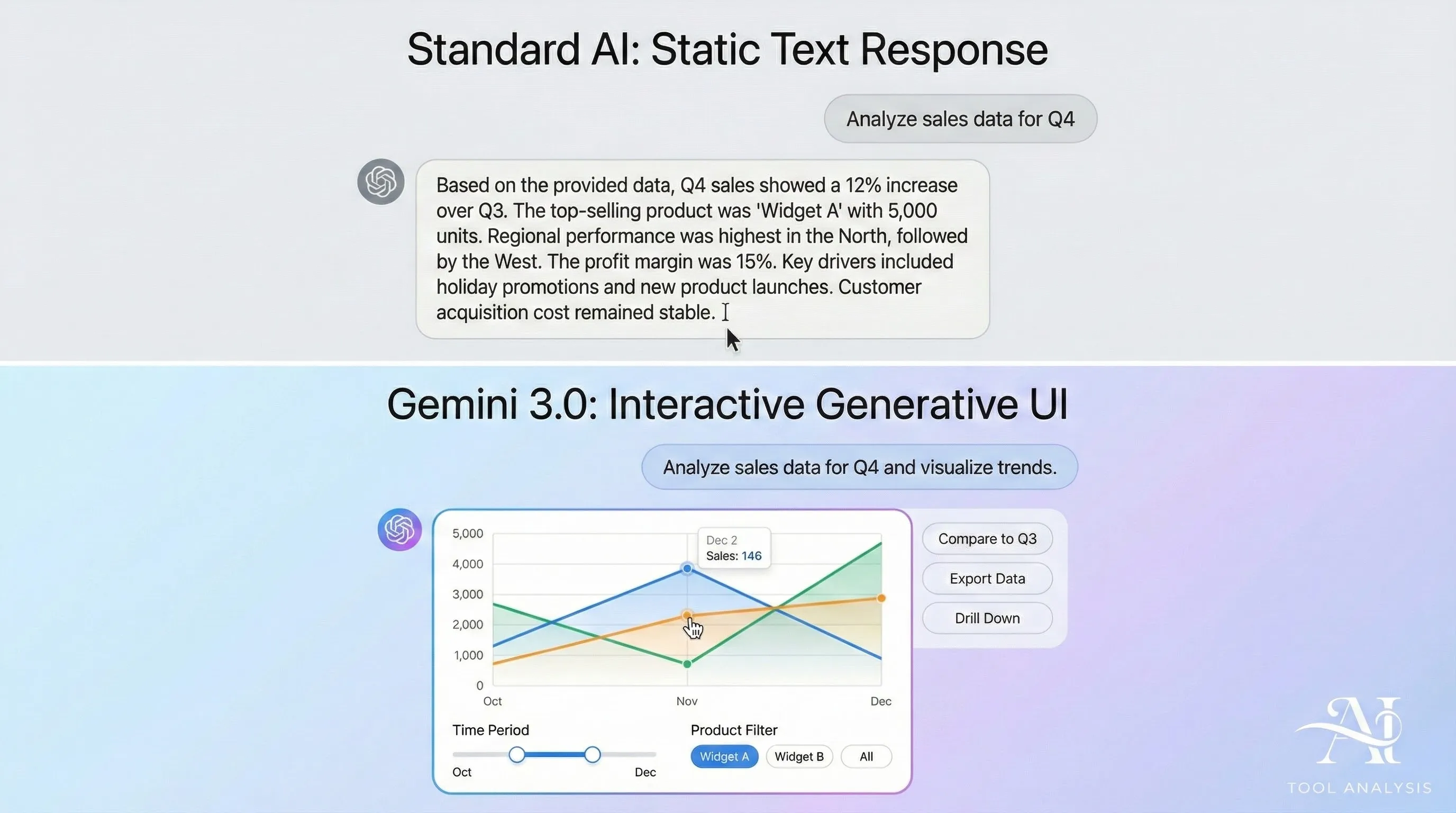
For frontend developers, this is a game-changer. You can describe an idea (e.g., “Create a minimalist dark theme dashboard”), and Gemini 3.0 generates the functional code and interface. This visual approach is a major differentiator from Claude 4.5.
🔍 REALITY CHECK: Gemini 3 Pro vs Deep Think
Marketing Claims: “Gemini 3.0 leads the world in reasoning.”
Actual Experience: Most users currently access Gemini 3 Pro (which is excellent). However, the absolute highest benchmark scores (like the 93.8% GPQA) are achieved by Gemini 3 Deep Think, a more computationally intensive (and likely expensive) version that is rolling out more slowly.
Verdict: Gemini 3 Pro is a major upgrade, but the PhD-level breakthroughs are primarily associated with the Deep Think configuration.
💻 Claude Opus 4.5: The Engineer’s Choice
Anthropic took a different path with Claude Opus 4.5. They focused intensely on reliability, enterprise needs, and making Claude the undisputed best tool for software engineering.
Reclaiming the Coding Crown
The headline feature of Opus 4.5 is its coding performance. On the SWE-Bench Verified benchmark—which tests an AI’s ability to resolve real-world GitHub issues—Claude Opus 4.5 achieved a record-breaking 80.9%.
This is a significant lead over Gemini 3.0 Pro (~76.2%). Anthropic emphasizes that Opus 4.5 is designed for “sophisticated AI agents that can reason, plan, and execute complex tasks with minimal oversight.”
New Features for Precision
Opus 4.5 introduced unique features tailored for precision work:
- The “Effort” Parameter: Developers can now choose between High, Medium, or Low effort levels. This controls the trade-off between response thoroughness (High) and token efficiency/speed (Low). This provides flexibility that Gemini 3.0 currently lacks.
- The “Zoom” Tool: For computer use tasks (like automated UI testing), Opus 4.5 can request a zoomed-in region of the screen to inspect small details or read fine print, improving accuracy when interacting with complex interfaces.
Why Engineers Trust Claude
The preference for Claude in engineering isn’t just about benchmarks. It’s about behavior.
- Reliability and Determinism: Claude is known for predictable outputs, especially during complex tool interactions. This makes it ideal for backend automation and data-heavy pipelines.
- Long-Horizon Coherence: The Claude 4.5 family is optimized for long-running tasks, reportedly maintaining coherence (staying on task) for over 30 hours of autonomous coding.
📊 Head-to-Head: The Benchmark War Decoded
The benchmarks paint a clear picture of specialization. It’s a trade-off between raw intellectual horsepower and practical application.
| Category | Benchmark | Gemini 3.0 (Google) | Claude Opus 4.5 (Anthropic) | Winner |
|---|---|---|---|---|
| Software Engineering | SWE-Bench Verified | ~76.2% (Pro) | 80.9% | 🏆 Claude |
| Terminal Coding | Terminal-Bench | 54.2% (Pro) | 59.3% | 🏆 Claude |
| Expert Knowledge | GPQA Diamond | 91.9% (Pro) / 93.8% (Deep Think) | 87.0% | 🏆 Gemini |
| Abstract Reasoning | ARC-AGI-2 | 31.1% (Pro) | 37.6% | 🏆 Claude |
| Complex Logic | HLE (No Tools) | 41.0% (Deep Think) | (Data N/A) | 🏆 Gemini |
💡 Swipe left to see all features →
Decoding the Results
The data shows a fascinating split. Gemini dominates traditional measures of complex logic and expert knowledge (HLE, GPQA).
However, Claude Opus 4.5 leads in the practical application of intelligence to software development (SWE-Bench, Terminal-Bench). Surprisingly, Claude 4.5 also pulls ahead in ARC-AGI-2 (abstract visual puzzles), scoring 37.6% vs Gemini 3 Pro’s 31.1%, indicating strong non-verbal problem-solving skills.
👨💻 Real-World Coding Test: Backend vs Frontend
To move beyond benchmarks, I tested both models on two common development tasks: a complex backend refactor and a frontend UI build from a mockup.
Backend Logic and Refactoring (Winner: Claude 4.5)
I gave both models a messy Python module responsible for data synchronization and asked them to refactor it for efficiency and add error handling.
Claude Opus 4.5 acted like a meticulous senior engineer. It analyzed the dependencies first and identified potential race conditions. The resulting code was clean, robust, and included comprehensive test cases. As developer Simon Willison noted after using Opus 4.5 for a large-scale refactoring, the model “was responsible for most of the work.”
Gemini 3.0 Pro was faster but less thorough. It successfully optimized the code but missed one edge case in the error handling that Claude caught. It required more human oversight to reach production quality.
Frontend UI Generation (Winner: Gemini 3.0)
Next, I uploaded a Figma mockup of a new dashboard visualization and asked both models to generate the React component.
Gemini 3.0 Pro excelled here. Its strong multimodal understanding and “vibe coding” capabilities allowed it to interpret the visual design accurately. The generated code and CSS closely matched the mockup, capturing nuances of spacing and layout.
Claude Opus 4.5 produced functional code, but the layout required significant tweaking. It focused more on the data structure than the visual presentation.
🤖 The Agentic Workflow Showdown
Both Google and Anthropic have heavily emphasized “agentic capabilities”—the ability for the AI to act autonomously, use tools, and complete multi-step tasks.
Claude 4.5 focuses on reliability and long-horizon execution. Anthropic emphasizes “deterministic” tool use—meaning predictable outputs when calling APIs or running commands. Features like the new “Tool Search” (allowing agents to dynamically discover tools) and the 30+ hour coherence make it ideal for complex enterprise automation.
Gemini 3.0 integrates agents through its new Antigravity platform (which we compared in our Antigravity vs Cursor review). Its superior reasoning allows for sophisticated planning, and its multimodal capabilities enable agents that can interact visually and auditorily.
Winner for Reliability: Claude 4.5. Its predictable behavior is crucial for backend automation.
Winner for Versatility: Gemini 3.0. Its multimodal strengths open up new possibilities for interactive agents.
🧠 Context Windows and Pricing
The economics and memory capacity of these models are major differentiators.
Context Windows (Memory)
- Claude Opus 4.5: 200,000 tokens (approx. 500 pages of text). (1M in beta for some users).
- Gemini 3.0 Pro: 1,000,000 tokens (approx. 1,500 pages or 1 hour of video).
Gemini 3.0’s massive context allows for analyzing entire codebases or long videos in a single prompt.
The Price War
The API pricing strategies are distinct and complex.
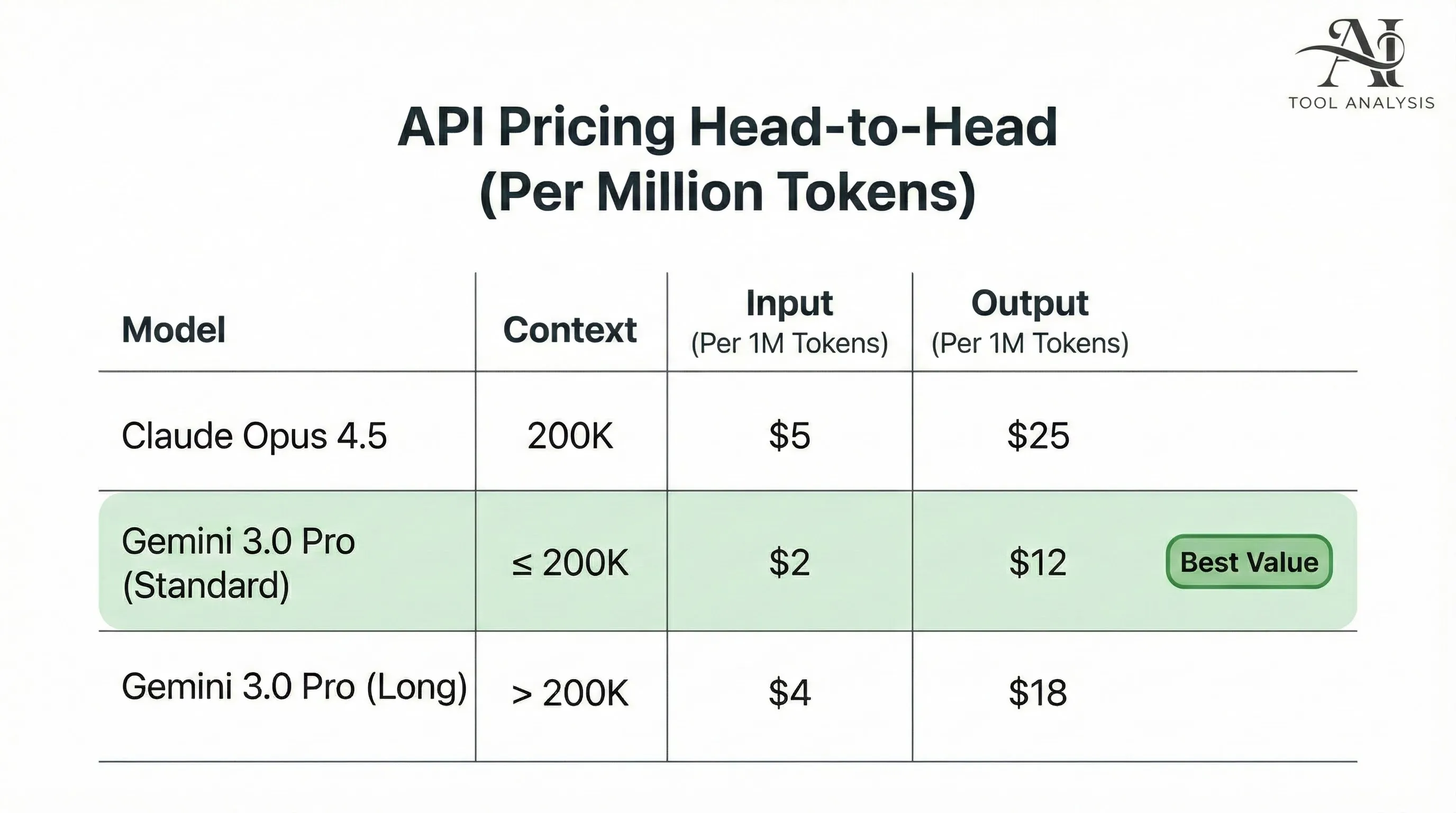
Claude Opus 4.5 Pricing: Anthropic dramatically cut the price by 66% compared to its predecessor.
- Input: $5 per Million Tokens (MTok)
- Output: $25 per MTok
Gemini 3.0 Pro Pricing: Google uses a tiered model based on context length:
Standard Context (≤ 200k tokens):
- Input: $2 per MTok
- Output: $12 per MTok
Long Context (> 200k tokens):
- Input: $4 per MTok
- Output: $18 per MTok
The Cost Comparison
For standard tasks, Gemini 3.0 Pro is less than half the price of Claude Opus 4.5. Even at the long context tier, Gemini remains cheaper. Google is aggressively pricing its model to gain market share.
🔍 REALITY CHECK: The Hidden Cost of Reruns
The Assumption: Cheaper per-token cost means lower overall cost.
The Reality: While Claude Opus 4.5 is more expensive upfront, its higher reliability in coding and lower hallucination rate can sometimes make it cheaper overall. If a cheaper model requires more reruns or human supervision to correct errors, the saved token costs evaporate.
Verdict: Consider the total cost of operation, including developer time. For mission-critical coding tasks, Claude’s higher “first-pass correctness” may justify the premium.
🗣️ Community Verdict: What Developers Are Saying
The developer community has been actively testing both models. Here’s a summary of the early sentiment in November 2025:
The Gemini 3.0 Vibe
Industry leaders have praised Gemini 3.0’s capabilities.
- Marc Benioff (Salesforce CEO): “Just spent 2 hours on Gemini 3. I’m not going back [to ChatGPT]. The leap is insane — reasoning, speed, images, video… everything is sharper and faster.”
- Andrej Karpathy (AI Researcher): Praised its “vibe-coding abilities” and called it “clearly a tier 1 LLM.”
- Frontend Focus: Users on Reddit agree that Gemini 3.0 is strong for UI and frontend tasks, leveraging its visual understanding well, although some report issues with it strictly following Figma designs in certain IDEs.
The Claude 4.5 Vibe
The sentiment around Claude 4.5 is overwhelmingly positive among software engineers focused on complex, reliable tasks.
- Trust and Reliability: Developers appreciate that Claude 4.5 is less likely to hallucinate functions or ignore instructions. One comparison noted: “For deeper refactors and test design, Claude 4.5 felt steadier.”
- Agentic Excellence: “Claude Code, imo, is still way way ahead of the game in terms of tooling. Skills, workflows, agent customization…” (Reddit user).
- Instruction Following: Many users find Claude superior in following complex instructions without drifting.
🤔 Who Should Use Which Model?
The choice between these two frontier models depends entirely on your primary use case, budget, and need for reliability.
Choose Claude Opus 4.5 If:
- You are a Software Engineer focused on Backend/Logic: Its 80.9% SWE-Bench score and meticulous approach make it the best for complex refactoring and bug fixing.
- You need Reliable Autonomous Agents: You require deterministic tool use and long-running coherence (30+ hours) for enterprise automation.
- Accuracy is Paramount: You are working on critical systems (finance, cybersecurity) where correctness matters more than creativity.
- You want control over quality vs. efficiency: The unique “Effort” parameter allows optimization of token usage.
Choose Gemini 3.0 Pro If:
- You are a Researcher or Data Scientist: Its superior reasoning (93.8% GPQA) makes it ideal for novel problem-solving and deep analysis.
- You need Massive Context Windows: You are analyzing very long documents, videos, or entire codebases (up to 1M tokens).
- You are a Frontend Developer or Designer: Its multimodal strengths and Generative UI capabilities excel at “vibe coding” and translating mockups into code.
- You prioritize Cost-Effectiveness: It is the cheaper option for general-purpose tasks and high-volume workloads.
❓ FAQs: Your Questions Answered
Which model is definitively “smarter,” Claude 4.5 or Gemini 3.0?
It depends on the definition. Gemini 3.0 (especially Deep Think) leads in complex, abstract reasoning and scientific knowledge (GPQA/HLE). Claude 4.5 leads in practical application, particularly in software engineering (SWE-Bench) and abstract visual puzzles (ARC-AGI-2).
Is Gemini 3.0 Pro cheaper than Claude Opus 4.5?
Yes, significantly. For standard context (<200k tokens), Gemini 3.0 Pro costs $2/$12 (input/output per M tokens), while Claude Opus 4.5 costs $5/$25. Gemini remains cheaper even at its higher long-context tier ($4/$18).
Which model is better for software development?
For backend logic, complex refactoring, and bug fixing, Claude Opus 4.5 is superior due to its reliability. For frontend development, UI generation from images (“vibe coding”), and algorithmic challenges, Gemini 3.0 Pro performs better.
What is Generative UI in Gemini 3.0?
Generative UI (GenUI) allows Gemini 3.0 to create interactive interfaces (like widgets with buttons, sliders, and graphs) dynamically in response to a prompt, rather than just generating static text.
What are the context window limits?
Claude Opus 4.5 has a 200,000 token limit (1M in beta for some). Gemini 3.0 Pro offers up to 1,000,000 (1 Million) tokens.
Which model is better for building autonomous AI agents?
Claude Opus 4.5 is generally considered superior for reliable autonomous agents. It excels at deterministic tool use, follows instructions precisely, and can maintain coherence for extremely long durations (30+ hours), which is crucial for complex workflows.
What is the “Effort” parameter in Claude 4.5?
The Effort parameter (unique to Opus 4.5) allows developers to control the trade-off between thoroughness and efficiency. You can choose Low Effort for faster, cheaper responses, or High Effort for maximum depth and capability on complex tasks.
When were these models released?
Both were released in November 2025. Google launched Gemini 3.0 on November 18th, and Anthropic launched Claude Opus 4.5 on November 24th.
🏁 Final Verdict: A Multi-Model Future
The week that Gemini 3.0 and Claude 4.5 launched marks a pivotal moment in the AI landscape. We are moving beyond the search for a single “best” model and entering an era of specialization.
In the battle of Claude 4.5 vs Gemini 3.0, the optimal approach for sophisticated users and businesses is a multi-model strategy—using the right tool for the job.
Our Recommendation
Use Claude Opus 4.5 for:
- Critical coding tasks (backend logic, complex refactoring).
- Reliable autonomous agent deployment and complex tool use.
- High-stakes enterprise automation where precision is key.
Use Gemini 3.0 Pro for:
- Deep research and scientific analysis (leveraging its superior reasoning).
- Multimodal projects (video/image understanding, Generative UI/”vibe coding”).
- Analyzing massive documents (leveraging the 1M context).
- Cost-effective general-purpose tasks.
The competition is fierce, driving innovation forward at an incredible pace. The real winners are the users who now have access to these specialized, powerful tools.
Stay Updated on Foundational Models and Developer Tools
The AI landscape is changing weekly. Don’t miss the next major model launch or benchmark breakthrough. Subscribe for weekly reviews of coding assistants, APIs, and the underlying AI models powering them.
- ✅ Honest, hype-free reviews
- ✅ Head-to-head comparisons
- ✅ Breaking news analysis
- ✅ Price drop alerts
- ✅ Practical use case guides
Related Reading
- Gemini 3.0 Review 2025: Google’s Reasoning Breakthrough
- Claude AI Review 2025: The Thoughtful Alternative (30-Day Test)
- Claude Code vs Gemini CLI: Which Terminal AI is Better?
- Cursor 2.0 Review: The AI-First Code Editor
- Grok 4 Review: Is xAI’s Model Competitive?
- AI News (Nov 20, 2025): Gemini 3 Launch and More
- ChatGPT Review 2025: The Industry Standard
Last Updated: November 29, 2025
Claude Version Tested: Opus 4.5 (claude-opus-4-5-20251101)
Gemini Version Tested: 3.0 Pro Preview (gemini-3-pro-preview)
Next Review Update: December 29, 2025 (Models updating frequently)