

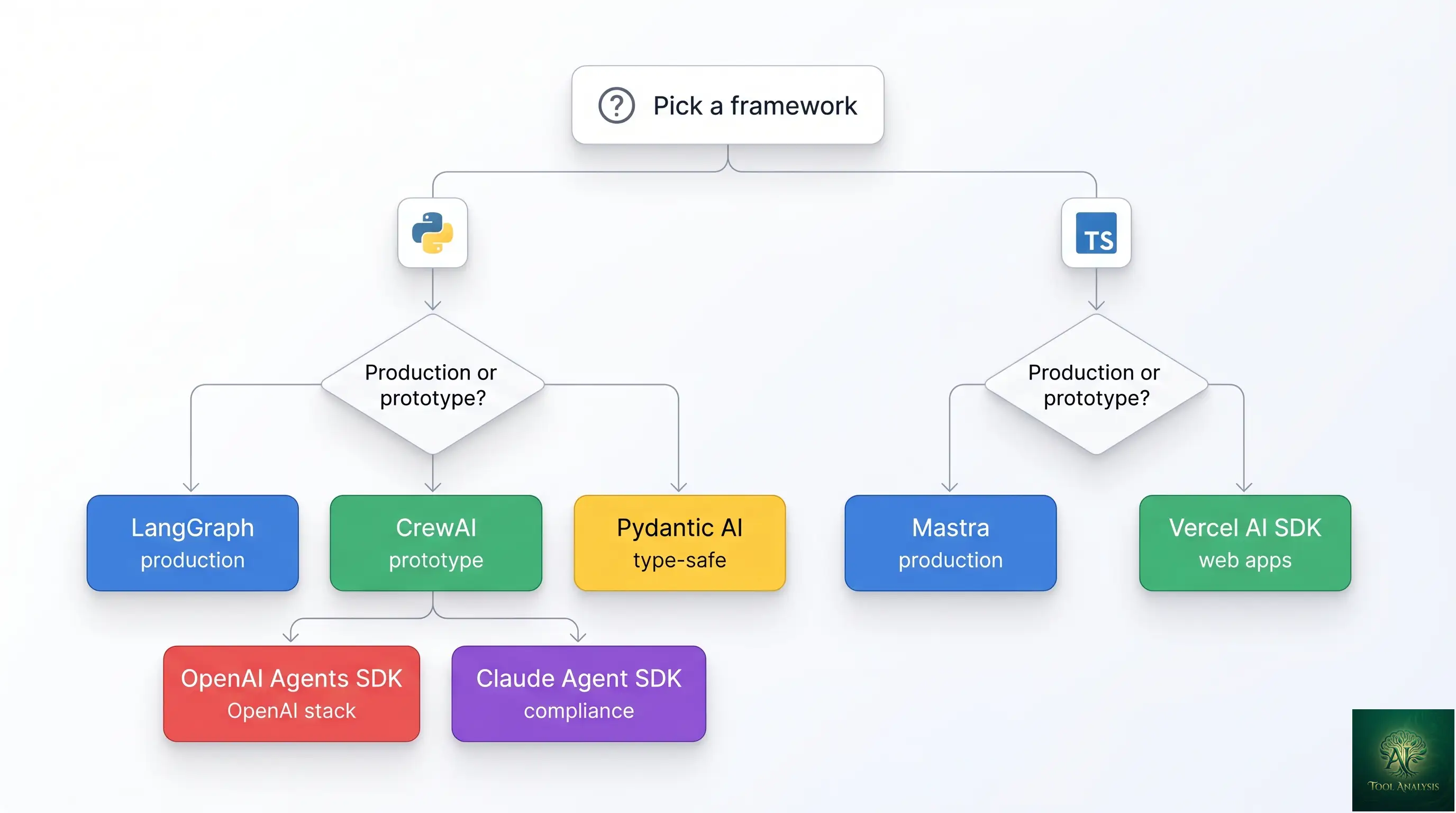
If you tried to pick an AI agent framework eighteen months ago, the field had four serious contenders and the choice was mostly LangChain (because everyone else used LangChain). In April 2026 the picture is more interesting: 11 credible frameworks, three distinct production tiers, two new design philosophies (TypeScript-first and type-safe Python), and a Model Context Protocol standard that’s reshaping integration patterns across every framework simultaneously. This guide is the decision tree for picking one — what each does best, where each falls short, and the honest answer to “should I just use LangGraph because everyone else does?”
⚡ TL;DR – The Bottom Line
What This Is: The April 2026 buyer’s guide to AI agent frameworks — covering 11 credible options across three production tiers, with explicit decision criteria for each.
Best For: Engineering teams choosing what to build their next agent system on. Both Python and TypeScript stacks covered.
Top Picks: LangGraph (Python production), CrewAI (Python prototyping), Mastra (TypeScript), OpenAI Agents SDK (OpenAI stack), Claude Agent SDK (compliance-sensitive).
Cost: Most frameworks are free + open-source. You pay for LLM API calls and (optionally) paid observability tooling like LangSmith or CrewAI Enterprise.
⚠️ The Catch: The 95%-to-99% reliability gap is real. Going from “working demo” to “production-ready” takes 5-10x more engineering than the initial build, regardless of framework choice.
📑 Quick Navigation
The Bottom Line: Three Picks by Use Case
Skip the deliberation if you fit one of these three buckets:
- Building a production multi-agent system on a Python team: LangGraph. Highest enterprise adoption (34.5M monthly downloads), built-in checkpointing with time-travel debugging via LangSmith observability, the most mature ecosystem. Steeper learning curve than CrewAI but the maturity premium is worth it for anything going to production.
- Prototyping a multi-agent crew this week: CrewAI. Fastest path from blank screen to working agent crew, lowest boilerplate-to-functionality ratio in the field, supports OpenAI/Anthropic/Ollama/any-OpenAI-compatible model, and has built-in semantic memory (the biggest capability gap in most other frameworks). Perfect for prototypes; less battle-tested for high-scale production.
- Building an AI feature inside a Next.js or Node.js app: Vercel AI SDK or Mastra. Vercel AI SDK is the clean lightweight option for chat-style features inside web apps. Mastra is the more substantive choice for full multi-agent systems on TypeScript stacks — it’s the framework Marsh McLennan deployed to 75,000 employees and SoftBank built their Satto Workspace platform on.
If you’re outside those three buckets — or you specifically need OpenAI’s clean handoff model, Anthropic’s safety-first design, type-safe Python, or visual drag-and-drop building — the rest of this guide walks through all 11 frameworks with the honest trade-offs.
Hype vs Reality: What Can Agents Actually Do in 2026?
The marketing pitch since 2023 has been some version of “deploy autonomous AI workers that replace your team.” The reality in April 2026 is more nuanced. Agents reliably handle well-scoped, lower-stakes work: generating drafts, doing initial research passes, executing repeatable tasks against APIs, formatting and routing data, drafting emails, summarizing documents. They struggle with anything requiring deep judgment in unfamiliar contexts, multi-hour focus on a single complex task, or work where a single mistake is catastrophic.
The gap between “demo working” and “shipping to production” is still real. The frameworks that ship reliable agents in 2026 (LangGraph, OpenAI Agents SDK, Claude Agent SDK) all share the same design discipline: explicit state management, observable execution, and the ability to checkpoint and resume. The frameworks that prototype fast (CrewAI, Vercel AI SDK) get you to “demo working” faster but require more scaffolding to get to “production stable.” Pick based on which side of that line your project is on.
What an AI Agent Framework Actually Does (The Engine vs Car Metaphor)
Useful framing borrowed from the systems-engineering tradition: the LLM is the engine, the agent framework is the car. The engine generates power (next-token prediction). The car is everything that turns power into useful motion — steering, transmission, brakes, dashboard, fuel system, body. By itself an LLM is a powerful but directionless thing; it can produce text but can’t decide which text matters, can’t track what it already tried, can’t call external services, can’t recover from failure.
An agent framework provides the “car” components: tool-calling infrastructure (the steering), state management and memory (the dashboard), planning and execution loops (the transmission), error handling and retry logic (the brakes), and observability (the windshield, so you can see what’s happening). Without these, you have a powerful LLM stuck idling in neutral. With them, you have something that can actually drive.
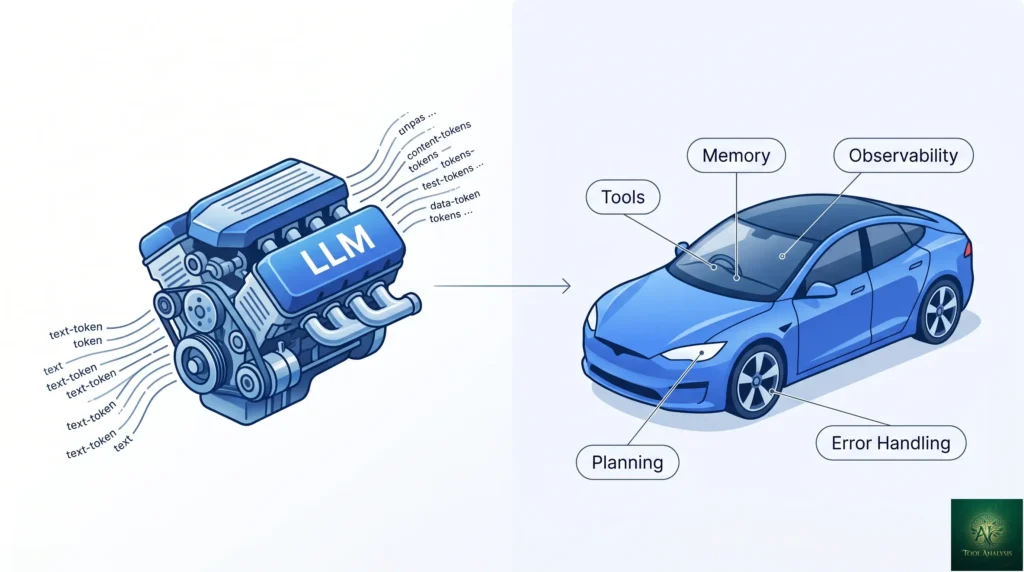
The Anatomy of an AI Agent
Every agent framework, regardless of brand, builds the same four components in different shapes. Understanding the components clarifies why the frameworks differ — they all ship the same parts but emphasize different ones.
1. The Brain (LLM + Profile)
An LLM (Claude Opus 4.7, GPT-5.5, Gemini 3 Pro, etc.) plus a system prompt that defines the agent’s role, expertise, and behavioral constraints. Most frameworks let you swap the underlying LLM with a config change. The “profile” — what the system prompt says about who the agent is — is where most prompt-engineering effort goes.
2. Planning & Execution Loop
The agent’s “decision-making cycle.” Frameworks implement this differently: ReAct loops (Thought → Action → Observation), explicit graph state machines (LangGraph), task delegation with hand-off (OpenAI Agents SDK, CrewAI), workflow-style flows (Mastra). The choice of execution model shapes everything else — debugging, observability, parallelism, recovery.
3. Memory
What the agent “remembers” across turns. Three layers in modern frameworks: short-term memory (conversation context within a single session), long-term memory (semantic knowledge across sessions, stored in vector DBs or similar), and procedural memory (learned skills and workflows). Built-in semantic memory is the biggest capability gap in 2026 — only CrewAI, Mastra, and Google ADK ship it natively. LangGraph offers checkpointing for state persistence, which is related but different (state-snapshot vs semantic-recall).
4. Tools
How the agent interacts with the outside world: function calling (custom Python/TS functions), API integrations (Slack, Salesforce, your database), code execution (sandboxed Python, JavaScript), browser automation, and increasingly MCP servers (Model Context Protocol — Anthropic’s standard for tool integration that’s now native in CrewAI, Vercel AI SDK, Mastra, and Microsoft Agent Framework). Tool quality often matters more than LLM choice; a smart agent with bad tools can’t accomplish anything useful.
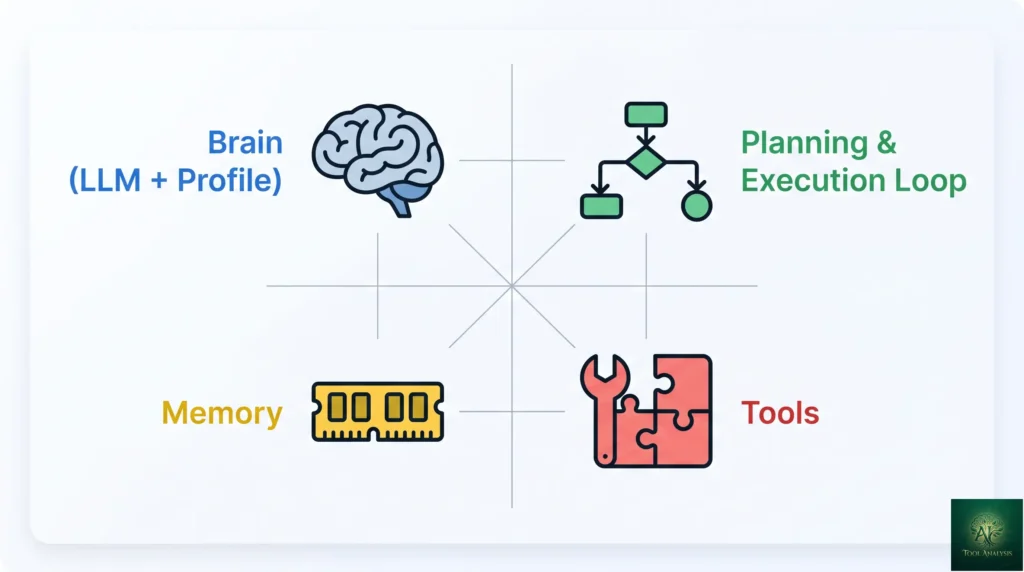
💡 Key Takeaway: The four components (Brain, Planning, Memory, Tools) are universal across every AI agent framework. The differences come down to which component each framework emphasizes — LangGraph emphasizes Planning (graph state machines), CrewAI emphasizes Memory (built-in semantic), OpenAI Agents SDK emphasizes clean handoff between agents. Pick the framework whose emphasis matches your project’s biggest design challenge.
Tier 1: Production-Ready Frameworks
The three frameworks below are what serious teams ship to production in April 2026. They share built-in observability, checkpointing/state persistence, and explicit-execution semantics.
LangGraph (the enterprise leader)
Spun out of LangChain as the next-generation graph-based execution model, LangGraph hit 34.5M monthly downloads as of early 2026 — by far the highest in the category. It’s used by major enterprise customers including Klarna, Uber, LinkedIn, and Replit. The core abstraction: agents as state machines with explicit nodes, edges, and shared state. The killer feature: time-travel debugging via LangSmith, where you can rewind execution to any prior state, inspect what the agent saw, and replay from there.
Strengths: most mature production tooling, best observability story, strong community. Weaknesses: steeper learning curve than CrewAI, requires explicit state design upfront. Best for: Python teams shipping multi-agent systems to production at scale.
OpenAI Agents SDK (the clean handoff model)
OpenAI’s official agent framework, released late 2025 and now the recommended path for OpenAI ecosystem builders. The killer abstraction: agents transfer control to each other explicitly, carrying conversation context, with each agent defined by instructions, model reference, tools, and a list of agents it can hand off to. Built-in tracing and guardrails. Cleanest mental model for multi-agent systems we’ve tested.
Strengths: smallest API surface, native OpenAI tracing, opinionated good defaults. Weaknesses: tightly coupled to OpenAI ecosystem, less flexibility for non-OpenAI models. Best for: Python teams already on OpenAI infrastructure who want minimal boilerplate.
Anthropic Claude Agent SDK
Anthropic’s framework, launched alongside Claude Opus 4.6 and refined through 4.7. Designed around safety-first principles and Claude’s extended thinking capability — agents can pause to “think” before acting, with the thinking traces inspectable for debugging and audit. Native MCP support; tight integration with Claude’s tool-use API.
Strengths: strongest safety posture for compliance-sensitive domains (healthcare, finance, legal), best Claude integration, audit-friendly. Weaknesses: Anthropic-only model support, smaller community than LangGraph or OpenAI’s SDK. Best for: teams in regulated industries or any team that’s standardized on Claude.
Tier 2: Rapid Prototyping & Specialized
CrewAI (fastest prototyping)
The framework with the lowest boilerplate-to-functionality ratio. Define agents (role + goal + backstory), tasks (description + expected output), and a crew (which agents handle which tasks); CrewAI handles the rest. Output passes between agents automatically; built-in semantic memory (rare); supports OpenAI, Anthropic, Ollama, and any OpenAI-compatible API. CrewAI Enterprise adds observability, guardrails, and team collaboration features.
Strengths: fastest demo-to-working time, built-in memory, multi-vendor model support. Weaknesses: less mature checkpointing than LangGraph, harder to debug at scale. Best for: prototypes, hackathons, MVPs, and any project where time-to-first-working-agent is the priority.
Pydantic AI (type-safe Python)
From the team behind Pydantic, the de-facto type-validation library for Python. Tailored for type-safe Python environments with Pydantic models for tool inputs/outputs and strong typing throughout. The killer feature for serious teams: configurable usage limits — caps on request tokens, response tokens, total tokens, and tool calls — that bake budget controls into agent configuration rather than relying on monitoring.
Strengths: type safety, budget controls, fits naturally into FastAPI/Pydantic codebases. Weaknesses: smaller ecosystem, fewer pre-built integrations than LangGraph. Best for: Python teams that already use Pydantic heavily and want type-safety guarantees throughout the agent layer.
Mastra (TypeScript-first)
The breakout TypeScript framework of 2025-2026 — Mastra. Mastra brings the LangGraph-style explicit-execution model to TypeScript codebases, with workflow primitives, native MCP support, built-in memory, and observability. Real-world traction: Marsh McLennan deployed a Mastra-based search tool to 75,000 employees, and SoftBank built their Satto Workspace platform on it.
Strengths: TypeScript-native, real enterprise deployments, full-stack-friendly, strong workflow abstractions. Weaknesses: newer than the Python frameworks, smaller community (but growing fast). Best for: Next.js / Node.js teams, full-stack TypeScript codebases, anyone whose team prefers TS over Python.
Vercel AI SDK (lightweight web AI)
Not a full agent framework so much as a lightweight toolkit for adding AI features to Next.js apps. Streaming UI primitives, tool-calling helpers, multi-vendor model support. Native MCP support shipped in early 2026. Best for: chat features, AI-assisted UIs, simple agent patterns inside web apps. Not the right tool for complex multi-agent systems.
Strengths: minimal boilerplate, perfect React/Next.js integration, streaming-first design. Weaknesses: not a full multi-agent framework, less suited to long-running autonomous tasks. Best for: AI features inside web apps where the user is in the loop.
Tier 3: Specialized & Legacy
- LangChain (the OG): The framework that started the category. Still actively maintained but most new builds use LangGraph. LangChain is now positioned as the broader ecosystem of components (chat models, vector stores, tools), with LangGraph as the agent execution model on top. If you’re starting fresh, go straight to LangGraph.
- Microsoft Agent Framework: Microsoft’s evolved AutoGen, now positioned as a broader enterprise-friendly framework with strong Azure integration. Native MCP support shipped in early 2026. Best for: teams deeply on Azure / Microsoft 365 stack.
- LlamaIndex: Started as the RAG framework, expanded into agents. Still the strongest choice if your primary use case is retrieval-augmented generation over private data; less differentiated for general agent workflows.
- Google Agent Development Kit (ADK): Google’s official agent framework. Built-in semantic memory (rare), strong Gemini integration, runs on Google Cloud Vertex AI. Best for: teams on Google Cloud with Gemini-first workflows.
- Dify (visual no-code): Drag-and-drop agent builder for non-developers and rapid prototyping. The most beginner-friendly option in the category but hits ceilings fast for complex multi-agent systems.
🔍 REALITY CHECK
Marketing Claims: “Build production-ready AI agents in minutes” (the pitch on most agent-framework landing pages).
Actual Experience: You can build a demo-ready agent in minutes. Building a production-ready agent — one that handles errors gracefully, has observable execution, recovers from LLM failures, respects budget limits, and won’t hallucinate destructive tool calls — takes weeks of iteration regardless of framework. The fastest frameworks (CrewAI) get you to “demo” fastest. The most mature frameworks (LangGraph, OpenAI Agents SDK, Claude Agent SDK) get you to “production” with the least scaffolding. Don’t conflate the two.
Verdict: If you’re prototyping, optimize for time-to-demo. If you’re shipping to production, optimize for the framework’s debugging and observability story — that’s where the real time goes once you’re past the demo.
📊 Production-Readiness Score (April 2026)
Subjective 0-10 score based on observability, checkpointing, error handling, and ecosystem maturity. Higher is better.
📬 Find this useful?
Get our weekly developer-tool reviews — new framework releases, pricing changes, honest comparisons.
Head-to-Head: Which Framework Wins on What
| Framework | Language | Production Ready | Memory Built-in | MCP Support | Best For |
|---|---|---|---|---|---|
| LangGraph | Python | High (LangSmith) | Checkpointing only | Community adapter | Enterprise multi-agent |
| OpenAI Agents SDK | Python | High | Limited | Native | OpenAI-stack teams |
| Claude Agent SDK | Python / TS | High | Limited | Native (Anthropic-built) | Compliance-sensitive |
| CrewAI | Python | Medium | Yes (semantic) | Native | Rapid prototyping |
| Pydantic AI | Python | Medium | Limited | Community adapter | Type-safe Python |
| Mastra | TypeScript | Medium-High | Yes (semantic) | Native | TS / Next.js teams |
| Vercel AI SDK | TypeScript | Medium (web only) | Limited | Native | Web app AI features |
| LangChain | Python / JS | Use LangGraph | Limited | Community adapter | Components, not agents |
| Microsoft Agent Framework | Python / .NET | Medium-High | Limited | Native | Azure / Microsoft stack |
| LlamaIndex | Python / TS | Medium (RAG-focused) | Limited | Community adapter | RAG over private data |
| Google ADK | Python | Medium | Yes (semantic) | Community adapter | Google Cloud / Gemini |
📐 Capability Profile: Top 5 Frameworks
Subjective 0-10 scoring across the dimensions that matter for AI agent framework buyers.
The 2026 Trends Shaping the Field
MCP (Model Context Protocol) is becoming the standard
Anthropic published MCP in late 2024 as an open standard for tool integration with LLMs. By April 2026 it’s widely adopted: native support shipped in CrewAI, Vercel AI SDK, Mastra, and Microsoft Agent Framework within the last six months. LangGraph, Pydantic AI, LlamaIndex, and Google ADK have community adapters. The practical impact: you can build a tool once as an MCP server and use it across any MCP-aware framework, and the existing MCP ecosystem (Slack, GitHub, Linear, Notion, hundreds more) is available to your agent without per-framework rewrites.
Semantic memory is the biggest capability gap
Only three frameworks ship genuine built-in semantic memory in April 2026: CrewAI, Mastra, and Google ADK. The rest either provide checkpointing (state-snapshot persistence — useful but different) or expect you to BYO memory via vector stores. Long-running agents with cross-session continuity remain disproportionately hard to build outside those three frameworks. Expect the gap to close in the next 12 months as more frameworks integrate the popular memory layers (Mem0, Letta, Zep) natively.
TypeScript is rising, type safety is differentiating
The agent-framework field was Python-only for two years. Mastra (TypeScript-first) and Vercel AI SDK (TS-native) broke that pattern in 2025-2026 and now carry real production deployments. Pydantic AI on the Python side took type safety as a primary design goal. Both shifts respond to the same underlying need: as agents move from prototypes to production, structured guarantees about what data flows where matter more than maximum flexibility.
Getting Started: The 15-Minute First-Agent Test
Best way to evaluate any agent framework: build the same simple multi-agent crew in three different frameworks and ship the one that took least friction. Suggested test task: a research crew with three agents — a Researcher (Google Search via tool), a Summarizer (turns search results into a 500-word brief), and an Editor (polishes the brief for publication). Measure setup time, debugging experience when things break, and clarity of the resulting code.
From our own testing of this exact crew across CrewAI, LangGraph, and OpenAI Agents SDK: CrewAI got us to a working crew in roughly 20 minutes (lowest boilerplate). LangGraph took about 45 minutes (more explicit state design upfront, but the resulting graph is easier to debug). OpenAI Agents SDK took about 30 minutes (clean handoff model, but tied us into OpenAI models). All three produced working crews; the choice between them came down to which feels right for the longer build, not which got us through the demo first.
The Developer Experience: Pain Points You’ll Hit
The debugging nightmare
Multi-agent systems are non-deterministic by design. The same prompt can produce different outcomes across runs because the LLM samples differently, agents make different tool choices, and intermediate steps cascade. The frameworks that take debugging seriously (LangGraph with LangSmith, OpenAI Agents SDK with built-in tracing, Mastra with workflow logs) are the ones that survive contact with production. Frameworks that don’t are fine for demos and miserable in production.
Reliability: the 99% problem
Most agent demos work 90-95% of the time. Going from 95% to 99% — the threshold required for most production use cases — takes 5-10x more engineering effort than the original 0-95% climb. This isn’t a framework problem; it’s an LLM-reliability problem that frameworks try to manage. Plan accordingly: budget weeks for the reliability climb, not days.
Prompt engineering hell
Every multi-agent system eventually becomes a prompt-engineering exercise. Small wording changes in agent instructions produce surprising behavior shifts. The frameworks with strong eval tooling (LangSmith, the OpenAI Agents SDK eval harness) make this manageable; the frameworks without eval support leave you tweaking prompts in the dark. Plan to invest in eval infrastructure early, regardless of framework.
🔍 REALITY CHECK
Marketing Claims: “Our framework is the most flexible / fastest / easiest” (every agent-framework landing page).
Actual Experience: No framework is universally best. The one that wins depends on (a) what language your team writes in, (b) how production-critical your agent is, (c) which LLM vendor you’re standardized on, and (d) whether you need built-in memory or can BYO. We tested all 11 frameworks against a standard research-crew benchmark; for serious production work, only LangGraph, OpenAI Agents SDK, Claude Agent SDK, and Mastra reliably hit the bar. CrewAI is a strong prototyping choice that needs more scaffolding for production. The others fit specific niches well but aren’t the right “default.”
Verdict: Pick based on your team’s language and your project’s production-readiness requirement, not based on which framework has the loudest marketing.
The Road Ahead: What’s Coming Next
Three trajectories visible in April 2026 that will shape the field through Q4 2026 and 2027.
Built-in memory consolidation: Expect more frameworks to ship native semantic memory in the next 6-12 months, likely by integrating Mem0, Letta, or Zep as default memory layers. The memory gap will close.
MCP becomes table stakes: The community adapters for LangGraph, Pydantic AI, LlamaIndex, and Google ADK will be replaced by native MCP support, likely by end of 2026. At that point, “what tools your agent can use” stops being a framework decision.
Vendor-specific SDKs win their niches: OpenAI Agents SDK and Claude Agent SDK will probably keep gaining share among teams standardized on those vendors, while LangGraph holds the multi-vendor enterprise crown. The “use one framework for everything” thesis will weaken; the “use the right framework per project” thesis will win.
FAQs
What is the difference between an AI agent framework and an LLM?
The LLM is the engine; the framework is the car. An LLM (Claude Opus 4.7, GPT-5.5, Gemini 3 Pro) generates text. A framework wraps the LLM with tool-calling, memory, planning, error handling, and observability — turning a text generator into something that can take actions in the world.
Are AI agent frameworks free?
Most are open-source and free to use (LangGraph, CrewAI, Pydantic AI, Mastra, Vercel AI SDK, LangChain, LlamaIndex, OpenAI Agents SDK, Claude Agent SDK, Microsoft Agent Framework). You pay separately for: the underlying LLM API calls (OpenAI, Anthropic, Google), observability tooling on paid tiers (LangSmith, CrewAI Enterprise), and infrastructure to host your agents.
Which framework is best for RAG (Retrieval-Augmented Generation)?
LlamaIndex remains the strongest RAG-focused framework — it started there. LangGraph and CrewAI both handle RAG well as part of broader agent workflows. For pure RAG without complex agent logic, LlamaIndex; for agentic RAG (agents that reason about what to retrieve), LangGraph.
What are multi-agent systems?
Systems where multiple agents collaborate on a task — typically by specializing (one researches, one drafts, one edits) and passing work between each other. Frameworks like CrewAI, LangGraph, OpenAI Agents SDK, and Mastra all support multi-agent patterns. Multi-agent systems are useful when the task naturally decomposes into specialized roles; they add complexity that’s not always worth it for simpler tasks.
Are AI agents reliable enough for production use?
For lower-stakes tasks where occasional errors are tolerable (drafting, research, summarization, internal tooling): yes, with appropriate guardrails. For high-stakes tasks where errors are catastrophic (financial transactions, legal decisions, irreversible actions): not yet, regardless of framework. The 95%-to-99% reliability gap is real and crossing it requires significant engineering investment.
Do I need to be an expert programmer to use these frameworks?
No, but you need basic programming literacy. CrewAI and Vercel AI SDK have the gentlest learning curves. Dify offers a visual no-code interface for non-programmers. LangGraph, Pydantic AI, and Microsoft Agent Framework expect more programming comfort. None of them are accessible to non-technical users without code.
What’s the biggest challenge when building AI agents?
Reliability. Going from a working demo (90-95% success rate) to a production system (99%+ success rate) takes 5-10x more engineering than the initial build. This is fundamentally an LLM-reliability problem that frameworks try to manage through observability, error handling, and evaluation tooling.
Can AI agents replace software developers?
No, not in 2026. Agents handle well-scoped repetitive tasks (drafting code, generating boilerplate, simple refactors) but require human judgment for architectural decisions, debugging non-trivial production issues, and most work that requires deep contextual understanding. Coding agents (Claude Code, Cursor, GitHub Copilot Agent Mode) are increasingly capable assistants but not replacements.
✅ State of the Category in 2026
- ✓ 11 credible frameworks (up from 4 in early 2025)
- ✓ TypeScript joined the field as a real option
- ✓ MCP standardizing tool integration across vendors
- ✓ Real enterprise deployments at 75K+ user scale (Mastra, LangGraph)
- ✓ Vendor SDKs (OpenAI, Anthropic) raised the production-quality floor
❌ What Still Falls Short
- ✗ Built-in semantic memory only in 3 frameworks
- ✗ The 95-to-99% reliability gap remains expensive
- ✗ Multi-agent debugging is still a nightmare without LangSmith-class tooling
- ✗ Framework choice still locks you to a language ecosystem
The agent framework category is meaningfully healthier than it was a year ago, with three production-ready Python options, two credible TypeScript options, and a real standardization push via MCP. One full star off because the 95-to-99% reliability gap remains the biggest unsolved problem.
💡 Key Takeaway: The biggest mistake teams make in 2026 isn’t picking the wrong AI agent framework — it’s picking too late. Spend two days deciding, build for two weeks, and switch only if you hit a specific limitation. Time spent in evaluation paralysis is time not spent on the agent-design decisions that actually matter for your project’s success.
Final Verdict: Which Framework Should You Choose?
The 2026 answer is “it depends on your stack and your stage.” For a Python team going to production, LangGraph remains the strongest default — the maturity, observability, and enterprise traction are all real. For a TypeScript team, Mastra or Vercel AI SDK depending on whether you want full multi-agent or just AI features. For prototyping at any stage, CrewAI gets you there fastest. For OpenAI- or Anthropic-standardized teams, the vendor SDKs (OpenAI Agents SDK, Claude Agent SDK) are increasingly the right call. For RAG-heavy work, LlamaIndex still wins.
The biggest mistake we see in 2026 isn’t picking the wrong framework — it’s picking too late. Teams spend weeks evaluating frameworks before writing any agent code, and then write code that any of the top three frameworks would have supported equally well. Pick one based on your team’s language and your production-readiness need, build something with it for two weeks, and switch only if you hit a specific limitation. The framework decision matters less than the agent-design decisions you’ll make once you start building.
Related Reading
- Claude Code Opus 4.7 Review — agent-style coding tool from Anthropic, built on the Claude Agent SDK
- Cursor AI Review 2026 — agentic IDE that demonstrates many of the same patterns these frameworks formalize
- GitHub Copilot Pro Review — Microsoft’s coding agent, built on similar agentic foundations
- Google Antigravity Review — agentic IDE for the Google AI stack
- Gemini Flash Review — the LLM family that powers many cheap-tier agents
- Lovable Review — agentic app builder demonstrating no-code agent patterns
- Best AI Developer Tools — broader catalog of dev tooling
- The Complete AI Tools Guide — buyer’s guide for picking the right tool from 200+ tested
Founder of AI Tool Analysis. Tests every tool personally so you don’t have to. Covering AI tools for 10,000+ professionals since 2025. See how we test →
Stay Updated on AI Agent Frameworks
The agent-framework field shifts every quarter. Subscribe for honest reviews of new releases, MCP integrations, and production deployments — delivered every Thursday at 9 AM EST.
- ✅ Honest Reviews: We actually test these frameworks, not rewrite press releases
- ✅ Framework Releases: New entrants and major version releases covered within days
- ✅ Production Stories: Real-world deployments and what works at scale
- ✅ Comparison Updates: Side-by-side benchmarks as the field shifts
- ✅ No Hype: Just the AI agent news that matters for your work
Free, unsubscribe anytime. 10,000+ professionals trust us.

Last Updated: April 28, 2026
Frameworks Tested: 11 — LangGraph, CrewAI, OpenAI Agents SDK, Anthropic Claude Agent SDK, Pydantic AI, Mastra, Vercel AI SDK, LangChain, Microsoft Agent Framework, LlamaIndex, Google ADK
Next Review Update: July 2026 (or sooner when major MCP-native releases ship)
Have a tool you want us to review? Suggest it here | Questions? Contact us