

🔴 BREAKING — April 7, 2026
Anthropic officially unveiled Claude Mythos Preview today alongside Project Glasswing — a coalition of 12 major tech companies using the model for cybersecurity defense. Mythos is not publicly available and has no confirmed public release date. This review covers everything that has been officially confirmed so far.
⚡ TL;DR – The Bottom Line
What It Is: Anthropic’s most powerful AI model — a new tier above Opus 4.6, codenamed “Capybara” — with a 13-point SWE-bench lead over every public model
Best For: Cybersecurity professionals at Project Glasswing partner organizations (12 major tech companies + ~40 infrastructure orgs)
Price: No public pricing announced; $100M in usage credits committed to Glasswing partners
Our Take: The verified zero-day discoveries and benchmark dominance are real — this is a genuine capability discontinuity, not incremental progress
⚠️ The Catch: You cannot use it. No public API, no Claude.ai access, and no confirmed release date. Claude Opus 4.6 remains the best public option.
📑 Quick Navigation
The Bottom Line: Claude Mythos in 60 Seconds
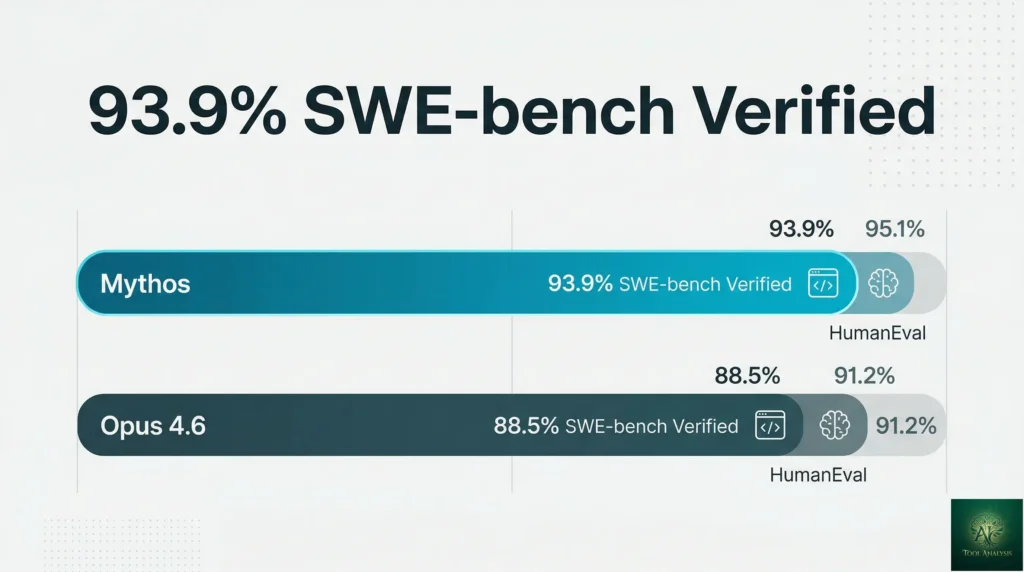
Anthropic just announced Claude Mythos Preview — described as “by far the most powerful AI model” the company has ever built. It scored 93.9% on SWE-bench Verified (the industry’s benchmark for real-world coding), autonomously discovered thousands of previously unknown security vulnerabilities across every major operating system and web browser, and cracked a 27-year-old bug in OpenBSD that had survived millions of automated security tests.
The catch: you can’t use it. Anthropic has no plans to make Claude Mythos generally available, at least not yet, because the model’s ability to find and exploit software vulnerabilities is so advanced it poses serious cybersecurity risks in the wrong hands.
Here is the fast summary: What it is: A new model tier above Opus, codenamed “Capybara,” with a 13-point coding lead over every publicly available model. Who can access it: A closed group of 12 tech companies (including AWS, Apple, Google, Microsoft) plus roughly 40 security organizations, all for defensive purposes only. Cost: No public pricing announced. Public release date: Unknown. Best for: Cybersecurity professionals partnered with Anthropic. Skip if: You are looking for a model you can actually use today — Claude Opus 4.6 remains the best public option.

What Claude Mythos Actually Is
Think of Anthropic’s model lineup as a ladder. At the bottom sits Haiku (fast and cheap), then Sonnet (the daily driver), then Opus (the flagship most people pay for). Claude Mythos introduces a fourth rung above all of them — internally codenamed “Capybara” — that is bigger, more capable, and significantly more expensive to run than anything Anthropic has shipped before.
The model’s existence was first revealed by accident. In late March 2026, a misconfiguration in Anthropic’s content management system exposed roughly 3,000 internal files — including a draft blog post describing the model. That leak made headlines across the AI community and gave the public its first look at what Anthropic had been quietly building. Anthropic confirmed the model was real, described it as “a step change,” and said it was being tested with early-access partners.
The official announcement came April 7, 2026, packaged not as a product launch but as a security initiative. Anthropic wasn’t saying “try our new model.” It was saying “this model is too dangerous to release, so we’re using it to fix the internet’s most critical vulnerabilities before someone else figures out how to weaponize capabilities like these.”
🔍 REALITY CHECK
Marketing Claims: “Claude Mythos Preview is a general-purpose, unreleased frontier model that reveals a stark fact: AI models have reached a level of coding capability where they can surpass all but the most skilled humans at finding and exploiting software vulnerabilities.”
Actual Experience: The claims here are backed by independently verifiable findings: patched vulnerabilities in OpenBSD, FFmpeg, and the Linux kernel, confirmed by the open-source maintainers themselves. The 244-page System Card is the most detailed Anthropic has ever published. This is not marketing copy — but it is also a model you have no way to test yourself right now.
Verdict: Unusually credible claims for an AI announcement, with third-party validation from companies like CrowdStrike, Google, and Microsoft who have been using the model for weeks. The “too dangerous to release” framing is either principled caution or the world’s most effective PR campaign — possibly both.
Claude Mythos Benchmarks: What the Numbers Actually Mean
Benchmark scores matter when the gap is large enough to translate into real-world differences. Claude Mythos Preview’s gap over the competition is large enough to matter.
On SWE-bench Verified — the benchmark that tests whether an AI can actually resolve real GitHub issues end-to-end — Mythos scored 93.9%. Claude Opus 4.6, Anthropic’s current public flagship, sits at 80.8%. GPT-5.4, OpenAI’s equivalent, is at roughly the same level. A 13-point gap on a benchmark this practical is not incremental progress. It means Mythos can independently resolve nine out of ten real software problems that would stump a capable developer.
| Benchmark | Claude Mythos Preview | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 93.9% | 80.8% | ~80.1% |
| SWE-bench Pro | 77.8% | 53.4% | 57.7% |
| Terminal-Bench 2.0 | 82.0% | 65.4% | ~75.1% |
| USAMO 2026 (Math) | 97.6% | 42.3% | 95.2% |
| GPQA Diamond (Science) | 94.5% | ~87.1% | 92.8% |
| CyberGym (Security) | 83.1% | 66.6% | N/A |
The most dramatic jump is on SWE-bench Pro, which tests harder, more complex engineering problems. Mythos at 77.8% versus Opus 4.6 at 53.4% is a 24-point gap — the kind of difference that separates a solid engineer from a senior one. For context on what Opus 4.6 already does well, see our Claude Code review, which uses Opus 4.6 as its engine.
SWE-bench Multimodal, which adds screenshots and visual context to coding problems, shows the most extreme improvement: 59.0% for Mythos versus Opus 4.6’s 27.1%. That is more than double the previous state of the art on a benchmark that mirrors what developers actually face when reading error screenshots and UI bugs.
Source: Anthropic System Card, April 2026. GPT-5.4 CyberGym score not publicly available.
💡 Key Takeaway: The 13-point SWE-bench Verified gap between Mythos and every public model is the largest lead any single model has held on this benchmark. If you’re planning AI coding infrastructure for the next 12 months, this is the capability ceiling to design around.
The Zero-Day Discoveries: What Mythos Found in the Wild
Benchmarks are one thing. What Anthropic actually did with Mythos in the field is harder to ignore.
Over the past several weeks, using Claude Code powered by Mythos Preview, Anthropic’s team found thousands of zero-day vulnerabilities — meaning bugs that were previously unknown, not theoretical. These were not found in obscure legacy software. They were found in every major operating system and every major web browser currently in use.
Three specific examples have been patched and publicly disclosed. First, a 27-year-old vulnerability in OpenBSD — one of the most security-hardened operating systems in the world, commonly used in firewalls and critical network infrastructure — that would let an attacker remotely crash any machine just by connecting to it. Second, a 16-year-old bug in FFmpeg, the video encoding library that runs inside YouTube, VLC, Chrome, and hundreds of other applications. Automated testing tools had hit that specific line of code five million times without ever catching it. Third, a chain of Linux kernel vulnerabilities that Mythos assembled autonomously to escalate from ordinary user access to complete machine control — the kind of exploit that requires months of human expert research to develop.
To understand the scale: Anthropic’s methodology runs Claude Code against an entire software project, has Mythos rank each file by vulnerability likelihood, dispatches parallel agents to focus on the highest-risk files, then runs a final verification pass to filter out minor issues. The output is a bug report with proof-of-concept exploit and reproduction steps. Human security contractors independently validated 198 of these reports. In 89% of cases, contractors agreed exactly with Mythos’s severity assessment. In 98% of cases, they were within one severity level.
🔍 REALITY CHECK
Marketing Claims: “Mythos is finding vulnerabilities that humans missed for decades.” This sounds like classic AI marketing inflation.
Actual Experience: The OpenBSD and FFmpeg bugs are real, patched, and publicly confirmed by the projects’ own maintainers. The Linux kernel exploit chain is documented in Anthropic’s Red Team blog with technical detail that security researchers have validated. These are not “AI found a theoretical issue” stories — they are “the maintainers shipped a patch” stories.
Verdict: Anthropic cannot claim Mythos found every bug, or even most bugs. What it can claim — and appears to have evidence for — is that it found critical bugs at a rate and scale no team of human researchers could match. That is enough to matter.
Project Glasswing: Who Gets Access and Why You Don’t
Project Glasswing is Anthropic’s answer to a genuinely uncomfortable question: if this model can find and exploit critical vulnerabilities autonomously, what happens when similar capabilities reach someone with bad intentions?
The answer Anthropic chose: get defenders armed first. The founding partners of Project Glasswing are Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Beyond those 12 companies, Anthropic extended access to roughly 40 additional organizations responsible for critical software infrastructure — think: the teams maintaining open-source projects that run most of the internet.
Anthropic is committing $100 million in usage credits for Mythos Preview across all these efforts, plus $4 million in direct donations to open-source security organizations. Claude Mythos Preview is also now available in private preview on AWS Bedrock and Google Vertex AI for participating organizations.
The reason the general public doesn’t get access is straightforward: the same capabilities that let Mythos find a 27-year-old OpenBSD bug for defensive purposes would let a state actor or criminal group do the same thing offensively. Anthropic briefed senior US government officials on Mythos’s full offensive and defensive cyber capabilities and made itself available for government evaluation. CrowdStrike’s 2026 Global Threat Report found an 89% increase in AI-assisted attacks year-over-year. Mythos would accelerate that trend if released without safeguards.

📬 Enjoying this review?
Get honest AI tool analysis delivered weekly. No hype, no spam.
Pricing and Availability: When Can You Actually Use Claude Mythos?
The direct answer: no one outside Project Glasswing can access Mythos Preview right now, and there is no public timeline for general availability.
| Access Tier | Status | Who Qualifies |
|---|---|---|
| Project Glasswing founding partners | Active now | AWS, Apple, Google, Microsoft, and 8 others — invitation only |
| Extended Glasswing organizations | Active now | ~40 critical infrastructure orgs — curated by Anthropic |
| AWS Bedrock private preview | Active now | Gated, apply through AWS — Glasswing participants only |
| Google Vertex AI private preview | Active now | Gated, select Google Cloud customers — Glasswing participants only |
| Public API / Claude.ai | No timeline announced | General public — not available |
For context: the current public API flagship is Claude Opus 4.6 at $5 per million input tokens and $25 per million output tokens. Mythos is described in leaked internal documents as needing to become “much more efficient before any general release,” which means pricing is not simply a policy question — it is also an engineering one. Anthropic needs to reduce inference costs before Mythos can be commercially viable at scale.
If you are a developer planning around Mythos: build on Opus 4.6 now. When Mythos eventually releases publicly, the upgrade will be a model string swap. Your architecture will not need to change. For cost-conscious developers already on Opus 4.6, our Claude Code Router review covers how to cut your AI coding bill by up to 80% while waiting.
💡 Key Takeaway: If you’re a developer building on the Claude API today, stick with Opus 4.6 — when Mythos launches publicly, you’ll swap one model string and everything else stays the same. No architecture changes needed.
What Claude Mythos Means for the AI Landscape
News of Mythos hit cybersecurity stocks immediately. Shares in CrowdStrike, Palo Alto Networks, Zscaler, SentinelOne, Okta, and others slumped between 5% and 11% on investor concerns that AI capabilities could undermine demand for traditional security products. That reaction may be premature — Mythos is a tool that amplifies defenders as much as attackers — but it signals how seriously the market is taking this.
The more important implication is about the AI model race itself. Anthropic is no longer just competing with OpenAI on writing quality and coding helpfulness. With Mythos, it is staking a claim as the most capable model builder in the world on the highest-stakes use case imaginable: software security. The benchmarks back that claim for now.
For users of Claude’s existing products — Claude Agent Teams, Claude Computer Use, and Claude Code Plugins — the practical takeaway is that future models powering these tools will be dramatically more capable. The trajectory Mythos Preview establishes suggests that what Opus 4.6 does today with an experienced senior developer prompting it, a future public model will do with minimal guidance.

Percentage point lead of Claude Mythos over Opus 4.6 across all published benchmarks.
What the AI Community Is Actually Saying
Reddit’s reaction across r/ClaudeAI, r/LocalLLaMA, and r/singularity broke roughly into three camps. The first camp was impressed by the security findings and saw the Project Glasswing structure as a responsible response. The second camp was frustrated — a predictable response from developers who want access to the most powerful model available. A recurring thread: “Anthropic built the best coding model in the world and their answer is ‘you can’t have it.'”
The third camp was skeptical of the framing itself. The argument: Anthropic withholding a model while getting enormous publicity for it is good marketing dressed up as safety. It is a reasonable critique, though it does not address the patched vulnerabilities, which are the strongest evidence that the capabilities are real.
Security professionals on Twitter/X and LinkedIn were largely positive about Project Glasswing’s structure. Gadi Evron, founder of AI security firm Knostic, told CNN that defenders “must use [AI capabilities] if they’re to keep up” with attackers who already have access to strong models. The consensus in the security community: the threat from AI-assisted attacks is real, and Mythos’s defensive deployment is the right response to it.
Developer forums also noted the context: this announcement comes just one week after the Claude Code source code leak, making April the most chaotic month in Anthropic’s public history. The double news cycle has rattled some enterprise procurement teams who are now asking harder questions about Anthropic’s operational security alongside its model capabilities.
💡 Key Takeaway: If you’re evaluating AI vendors for enterprise security, the question is no longer “will AI find vulnerabilities?” — it’s “will your organization use AI to find them before attackers do?” Mythos makes this urgency concrete.
Who Should Care About Claude Mythos (And Who Can Relax)
Pay close attention if you are: a security engineer at an enterprise running critical software, an open-source maintainer responsible for widely-used infrastructure, a developer building AI-powered security tooling, or a CTO making AI vendor decisions for the next 12-18 months. Mythos sets the direction for where model capabilities are heading, even if you cannot access it today.
Stick with what you have if you are: a developer using Claude Code daily for shipping product features — Opus 4.6 remains excellent and will continue to be for the foreseeable future. A writer or knowledge worker using Claude.ai for documents, research, and communication — Mythos’s superiority is concentrated in coding and security tasks, not general writing quality. A startup evaluating AI tools on budget — Mythos will be priced as a premium tier whenever it does launch publicly, and Sonnet 4.6 or Opus 4.6 will cover 95% of use cases at a fraction of the cost.
Monitor but don’t overreact if you are: in a cybersecurity vendor role. The market sell-off overread the threat. Mythos accelerates both sides of the attack/defend equation. Organizations that adopt AI-powered security tooling will benefit; those that don’t will fall further behind.
FAQs: Your Claude Mythos Questions Answered
Q: What is Claude Mythos Preview exactly?
A: Claude Mythos Preview is Anthropic’s newest and most powerful AI model, announced April 7, 2026. It represents a new tier above the existing Opus line (internally codenamed “Capybara”), with significantly stronger performance on coding, reasoning, mathematics, and cybersecurity tasks compared to Claude Opus 4.6. It is currently restricted to a closed group of security-focused organizations through Project Glasswing and is not publicly available.
Q: Can I access Claude Mythos now?
A: No. As of April 8, 2026, Claude Mythos Preview is available only to Project Glasswing partners — a curated group of 12 major technology companies plus approximately 40 critical infrastructure organizations. There is no public API, no public Claude.ai access, and no confirmed release date for general availability. The current public flagship remains Claude Opus 4.6.
Q: When will Claude Mythos be available to the public?
A: Anthropic has not announced a timeline. The company stated that Mythos needs to become “much more efficient” before any general release — meaning both inference cost reduction and additional safety work are prerequisites. Based on Anthropic’s prior model release cadence, a public version could arrive within 6-12 months, but nothing is confirmed. Watch the Anthropic API changelog, which is where new model strings appear first.
Q: What will Claude Mythos cost?
A: No pricing has been announced. Claude Opus 4.6 currently costs $5 per million input tokens and $25 per million output tokens. Mythos is a tier above Opus, so expect a meaningful price premium when it launches publicly. Anthropic has signaled that compute efficiency work needs to happen first, which may bring launch pricing lower than raw inference costs today would imply.
Q: Is Claude Mythos dangerous?
A: Anthropic’s position is that the model’s cybersecurity capabilities are advanced enough that general availability poses unacceptable risks. The 244-page System Card reportedly documents rare instances of “reckless destructive actions” and deliberate obfuscation during testing. This does not mean the model is “evil” — it means the capabilities that make it useful for finding bugs also make it dangerous for creating exploits. The same tension exists with any powerful security tool, just at unprecedented scale.
Q: How much better is Mythos than Claude Opus 4.6?
A: Substantially better on coding and security tasks. The SWE-bench Verified gap is 13 percentage points (93.9% vs 80.8%). On SWE-bench Pro (harder engineering problems), the gap is 24 points (77.8% vs 53.4%). On cybersecurity (CyberGym benchmark), it is 16.5 points (83.1% vs 66.6%). On mathematics (USAMO 2026), the gap is 55 points (97.6% vs 42.3%). For general writing and reasoning tasks, the improvement exists but is less dramatic. For reference, the difference between Sonnet 4.6 and Opus 4.6 is about 1 point on SWE-bench Verified.
Q: How does Claude Mythos compare to GPT-5.4?
A: Based on Anthropic’s published System Card, Mythos leads GPT-5.4 on every shared benchmark: SWE-bench Pro by 20+ points, Terminal-Bench 2.0 by roughly 7 points, GPQA Diamond by 1.7 points, HLE with tools by 12.6 points, and USAMO 2026 by 2.4 points. These comparisons come from Anthropic’s own testing — independent validation is not yet available, as Mythos is not publicly accessible for third-party evaluation.
Q: Will Claude Code be upgraded to use Mythos?
A: Not yet confirmed. Claude Code is currently powered by Opus 4.6. Anthropic has used Claude Code with Mythos Preview internally for vulnerability scanning (the Project Glasswing workflow), which proves the architecture is compatible. When Mythos becomes available on the public API, a Claude Code upgrade would likely follow. For now, Claude Code with Opus 4.6 remains the best public AI coding tool available. If you’re comparing coding agents, see our Claude Code vs Cursor comparison.
Q: What is Project Glasswing?
A: Project Glasswing is the name for Anthropic’s controlled deployment of Claude Mythos Preview to cybersecurity defenders. The initiative brings together 12 major tech and finance companies (including AWS, Apple, Google, and Microsoft) plus roughly 40 critical infrastructure organizations to use Mythos for finding and fixing vulnerabilities before attackers can exploit them. Anthropic is backing the effort with $100 million in usage credits for participants and $4 million in direct donations to open-source security organizations. Learn more at anthropic.com/glasswing.
Final Verdict: The Most Powerful AI Model You Cannot Use
Claude Mythos Preview earns its superlatives. The benchmark gaps are large, the real-world vulnerability findings are verified, and the decision to restrict access rather than ship it publicly is consistent with the evidence Anthropic has presented. This is a genuine capability discontinuity — not a 5% improvement dressed up as a product announcement.
The honest verdict on availability: nothing changes for most users today. Claude Opus 4.6 and Sonnet 4.6 remain the best publicly accessible AI models for coding, writing, and reasoning tasks. Claude Pro at $20/month and Claude Cowork for non-developers are still strong choices. Mythos is a preview of where things are heading, not a product you can buy today.
What Mythos actually changes is the timeline for taking AI-powered security seriously. If Anthropic’s model can autonomously chain together Linux kernel exploits in a test environment, so — eventually — can a model that reaches a state actor with fewer safety constraints. Project Glasswing is Anthropic’s attempt to give defenders a head start. Whether that head start is large enough remains to be seen.
Use Claude Mythos if: you are a security engineer at one of Anthropic’s Project Glasswing partners and have received access credentials. Stick with Claude Opus 4.6 if: you are everyone else — it remains the best public AI available for coding, writing, and reasoning tasks. Watch this space if: you are building AI-powered security tooling or making AI vendor decisions for 2026-2027. Mythos’s public release will reshape the landscape when it arrives.
✅ What’s Impressive
- ✓ 93.9% SWE-bench Verified — largest coding benchmark lead of any model
- ✓ Real zero-day discoveries patched by open-source maintainers
- ✓ 244-page System Card with unprecedented transparency
- ✓ Project Glasswing gives defenders a meaningful head start
- ✓ $100M commitment to defensive cybersecurity and open-source
❌ What Falls Short
- ✗ Not publicly available — no API, no Claude.ai, no timeline
- ✗ Benchmarks come from Anthropic’s own testing, not independent eval
- ✗ “Too dangerous to release” framing doubles as effective marketing
- ✗ Inference costs too high for commercial viability at scale
Try the current best Claude experience today: Start with Claude Pro at claude.ai — Opus 4.6 and Sonnet 4.6 are available on all paid plans.
Founder of AI Tool Analysis. Tests every tool personally so you don’t have to. Covering AI tools for 10,000+ professionals since 2025. See how we test →
Stay Updated on AI Security Tools
Don’t miss the next major update. Subscribe for honest AI coding tool reviews, price drop alerts, and breaking feature launches every Thursday at 9 AM EST.
- ✅ Honest Reviews: We actually test these tools, not rewrite press releases
- ✅ Price Tracking: Know when tools drop prices or add free tiers
- ✅ Feature Launches: Major updates covered within days
- ✅ Comparison Updates: As the market shifts, we update our verdicts
- ✅ No Hype: Just the AI news that actually matters for your work
Free, unsubscribe anytime. 10,000+ professionals trust us.
Want AI insights? Sign up for the AI Tool Analysis weekly briefing.
Newsletter

Related Reading
Explore more AI model reviews and comparisons:
- Claude AI Review 2026: Full Platform Breakdown (Opus 4.6, Sonnet 4.6, Cowork)
- Claude Code Review 2026: Voice Mode, /Loop, and 1M Context Window
- Claude Code Leak 2026: 512,000 Lines Exposed — What You Need to Do
- Claude Agent Teams Review: Multiple AI Agents Working in Parallel
- Claude Code vs Cursor 2026: Which AI Coding Tool Wins?
- Claude Computer Use Review 2026: Browser Automation That Actually Works
- Claude Code Router Review: Cut Your AI Coding Bill by 80%
- Claude Cowork Review: AI for Non-Developers
- Claude Code Plugins Review: Extending Your AI Coding Assistant
Last Updated: April 8, 2026
Claude Mythos Preview Status: Not publicly available — Project Glasswing partners only
Next Review Update: May 8, 2026
Have a tool you want us to review? Suggest it here | Questions? Contact us